ElasticSearch
本文最后更新于 2024-04-09,欢迎来到我的Blog! https://www.zpeng.site/
ElasticSearch
1.简介
Elasticsearch(ES) 是一个基于 Apache Lucene 开源的分布式、高扩展、近实时的搜索引擎,主要用于海量数据快速存储,实时检索,高效分析的场景。通过简单易用的 RESTful API,隐藏 Lucene 的复杂性,让全文搜索变得简单。
ES 功能总结有三点:
分布式存储
分布式搜索
分布式分析
因为是分布式,可将海量数据分散到多台服务器上存储,检索和分析,只要是海量数据需要完成上面这三种操作的业务场景,一般都会考虑使用 ES,比如维基百科,Stack Overflow,GitHub 后台均有使用。
2.特点功能
特点
ES 为什么这么受欢迎,得益于其相较于传统数据库所拥有的强大功能。
ES 不是什么新技术,主要是将全文检索、数据分析以及分布式技术结合在一起,形成了独一无二的 ES;
数据库的功能面对很多领域是不够用的,比如全文检索,同义词处理,相关度排名,复杂数据分析,海量数据的近实时处理;ES 作为传统数据库的一个补充,提供了数据库所不不能提供的很多功能;
可以作为一个大型分布式集群(数百台服务器),处理 PB 级数据,服务大公司;也可以运行在单机上,服务小公司;
对用户而言,开箱即用,非常简单,作为中小型的应用,分钟级部署,就可以作为生产环境的系统来使用了。
ES 底层基于 Lucene 开发,针对 Lucene 的局限性,ES 提供了 RESTful API 风格的接口、支持分布式、可水平扩展,同时它可以被多种编程语言调用。
ES 除了进行全文检索,也支持聚合/排序。随着 ES 功能越来越强大,其和传统数据库的边界越来越模糊。我们既可以把 ES 当作搜索引擎来使用,也可以将其作为传统关系型数据库来使用。
功能
全文搜索:Elasticsearch提供强大的全文搜索功能,可以处理大量的文本数据,并返回与搜索查询匹配的相关结果。它支持复杂的查询语法和高级搜索功能,如模糊搜索、多字段搜索、布尔搜索等
实时数据分析:Elasticsearch能够接收和索引大规模的实时数据,并提供快速的分析和聚合能力。它支持复杂的聚合操作,如平均值、最大值、最小值、分组统计等,使用户可以轻松地对数据进行深入分析
分布式和可扩展性:Elasticsearch采用分布式架构,数据可以在多个节点上进行分片和复制,以实现高可用性和横向扩展能力。这使得它可以处理大规模的数据集,并处理高并发的搜索和分析请求
实时数据同步:Elasticsearch支持实时数据同步和更新。当数据发生变化时,它能够快速地将新的或更新的数据索引到适当的位置,以保持索引与源数据的同步
日志和事件管理:Elasticsearch广泛应用于日志和事件管理领域。它可以集成日志收集工具(如Logstash)来实时索引和分析大量的日志数据,以便进行故障排除、监控和安全分析等任务
3.相关工具
下面就来学习与 Elasticsearch 相关的产品以及各种产品相结合的解决方案。
Logstash
Logstash 是一个动态数据收集管道,它拥有可扩展的插件生态系统,支持从不同来源收集数据和转换数据(过滤和处理),并将转换后的数据发送到不同的存储库中。Logstash 能够与 Elasticsearch 强力协同工作,2013 年 Logstash 被 Elastic 公司收购。
Logstash 具有如下特点:
实时性。可实时解析数据并对数据进行过滤处理。
可扩展性。具有200多个插件,可接收的数据来源有文本数据以及Redis、Kafka、MQ等存储的数据。
可靠性与安全性。Logstash会通过持久化队列来保证至少将数据送达一次,同时对数据进行传输加密。
实时监控能力。对可以接收的数据源进行监控,一旦数据源产生新的数据就立刻传输。
Elasticsearch
Elasticsearch 可以对数据进行全文搜索、分析和存储,它是基于JSON的分布式数据搜索和数据分析引擎,是专门为实现架构的水平可扩展性、高可靠性和管理便捷性而设计的产品。
Elasticsearch 的实现主要分为以下几个步骤:
用户将数据提交到 Elasticsearch 数据库中。
通过分词控制器对对应的语句进行分词。
将分词结果和权重(原始数据和分词内容的匹配度)一起存储,当用户搜索数据时,根据权重对搜索结果进行排名和打分(分数越高,匹配度就越高),最终将结果呈现给用户。
Kibana
Kibana 可以实现数据可视化,它的作用是在 Elasticsearch 中对数据进行管理和展示。它能够通过图表的形式把数据呈现给用户。
Kibana 具有高可扩展的用户界面,能够全方位地管理 Elasticsearch 中的数据。Kibana 最早的时候是基于 Logstash 创建的工具,具有如下特点:
Kibana 可以提供各种可视化的图表,只需要简单地配置即可。
Kibana 可以通过机器学习技术对异常情况进行检测,以提前发现可疑的问题。
Beats
Beats 是一款轻量级的数据采集器,用Go语言编写,并且集合了多种单一用途的数据采集器。这些采集器安装后可用作轻量型代理服务器,从成千上万台机器向Logstash或Elasticsearch发送数据。
Beats 具有如下几个特征:
Beats 是数据采集的得力工具。只要将采集器安装在服务器中,它们就会把数据汇总到 Elasticsearch 中。如果需要更加强大的处理性能,Beats 还能将数据输送到 Logstash 中进行转换和解析。
Beats 中集合的每款开源采集器都是以libbeat(用于转发数据的通用库)为基石的,用户需要监控某个专用协议时,可以自主构建采集器。
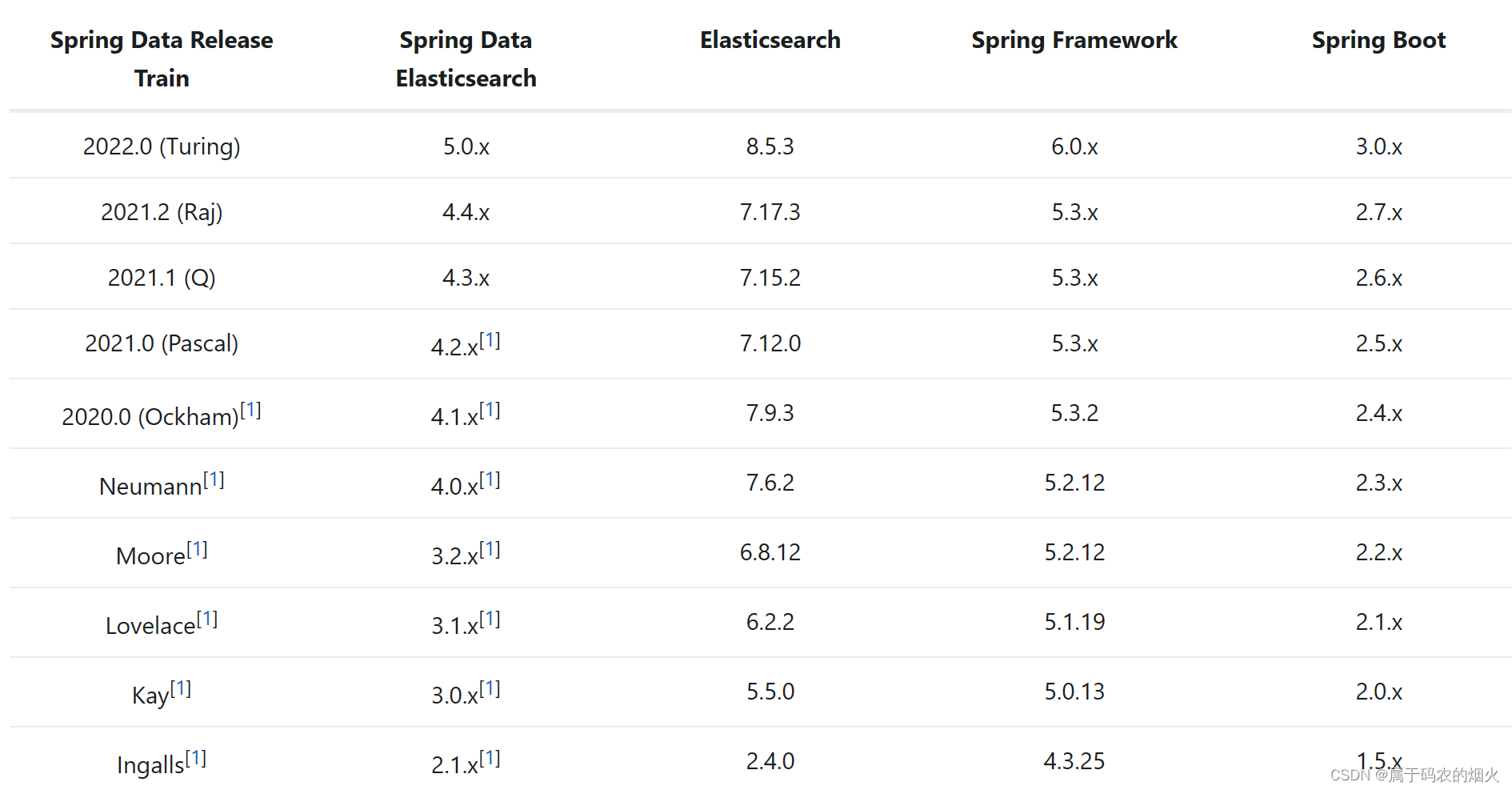
4.版本选择
为了避免使用的Elasticsearch版本和SpringBoot采用的版本不一致导致的问题,尽量使用一致的版本。下表是对应关系:
5.下载安装ElasticSearch
下载
SpringBoot版本:2.6.13
elasticsearch版本:7.15.2
<properties>
<java.version>1.8</java.version>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<spring-boot.version>2.6.13</spring-boot.version>
</properties>https://www.elastic.co/cn/downloads/elasticsearch
https://www.elastic.co/cn/downloads/past-releases#elasticsearch
https://www.elastic.co/cn/downloads/past-releases/elasticsearch-7-15-2
启动步骤
对映版本下载上面的安装包
解压到任意目录
启动es /bin/elasticsearch.bat
查看安装结果,在网页输入localhost:9200或者http://127.0.0.1:9200/,出现下图即为成功
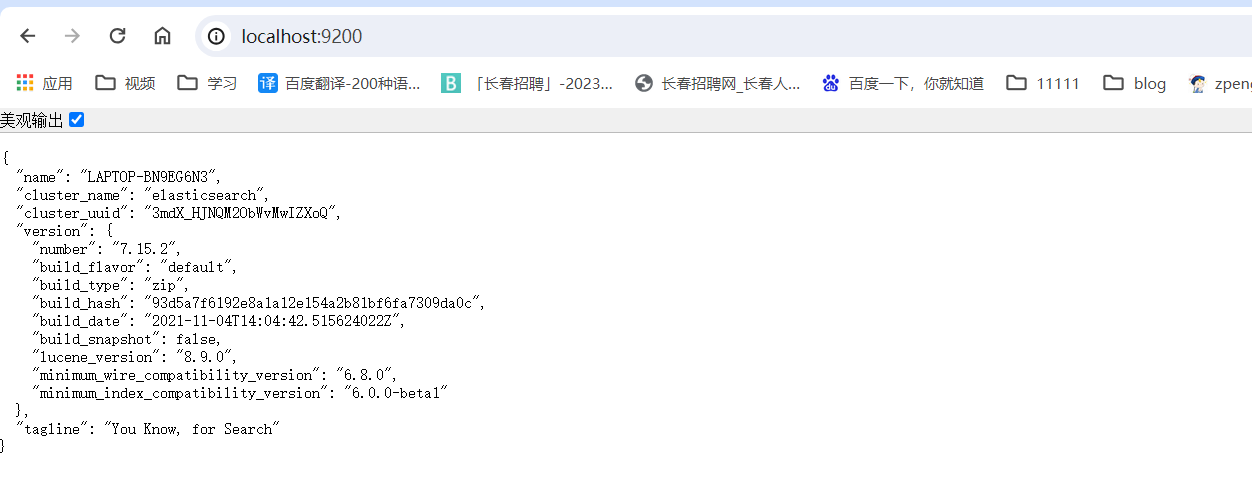
{
"name": "LAPTOP-BN9EG6N3",
"cluster_name": "elasticsearch",
"cluster_uuid": "3mdX_HJNQM2ObWvMwIZXoQ",
"version": {
"number": "7.15.2",
"build_flavor": "default",
"build_type": "zip",
"build_hash": "93d5a7f6192e8a1a12e154a2b81bf6fa7309da0c",
"build_date": "2021-11-04T14:04:42.515624022Z",
"build_snapshot": false,
"lucene_version": "8.9.0",
"minimum_wire_compatibility_version": "6.8.0",
"minimum_index_compatibility_version": "6.0.0-beta1"
},
"tagline": "You Know, for Search"
}注意: 9300 端口为 Elasticsearch 集群间组件的通信端口,9200 端口为浏览器访问的 http协议 RESTful 端口。
目录
将elasticsearch-7.15.2-windows-x86_64.zip文件解压出来
进入解压后的文件目录
bin目录 主文件目录
elasticsearch文件为Linux环境下的启动脚本
elasticsearch.bat文件为Windows环境下的启动脚本
config 配置文件目录
elasticsearch.yml文件为elasticsearch的配置文件
jdk jdk环境目录,es自带jdk环境目录,所以可以直接指定该目录为jdk目录。(ElasticSearch 5.x 往后依赖于JDK 1.8的)。
默认安装包带有 jdk 环境,如果系统配置 JAVA_HOME,那么使用系统默认的 JDK,如果没有配置使用自带的 JDK,一般建议使用系统配置的 JDK。
出现问题
"warning: usage of JAVA_HOME is deprecated, use ES_JAVA_HOME"
解决:
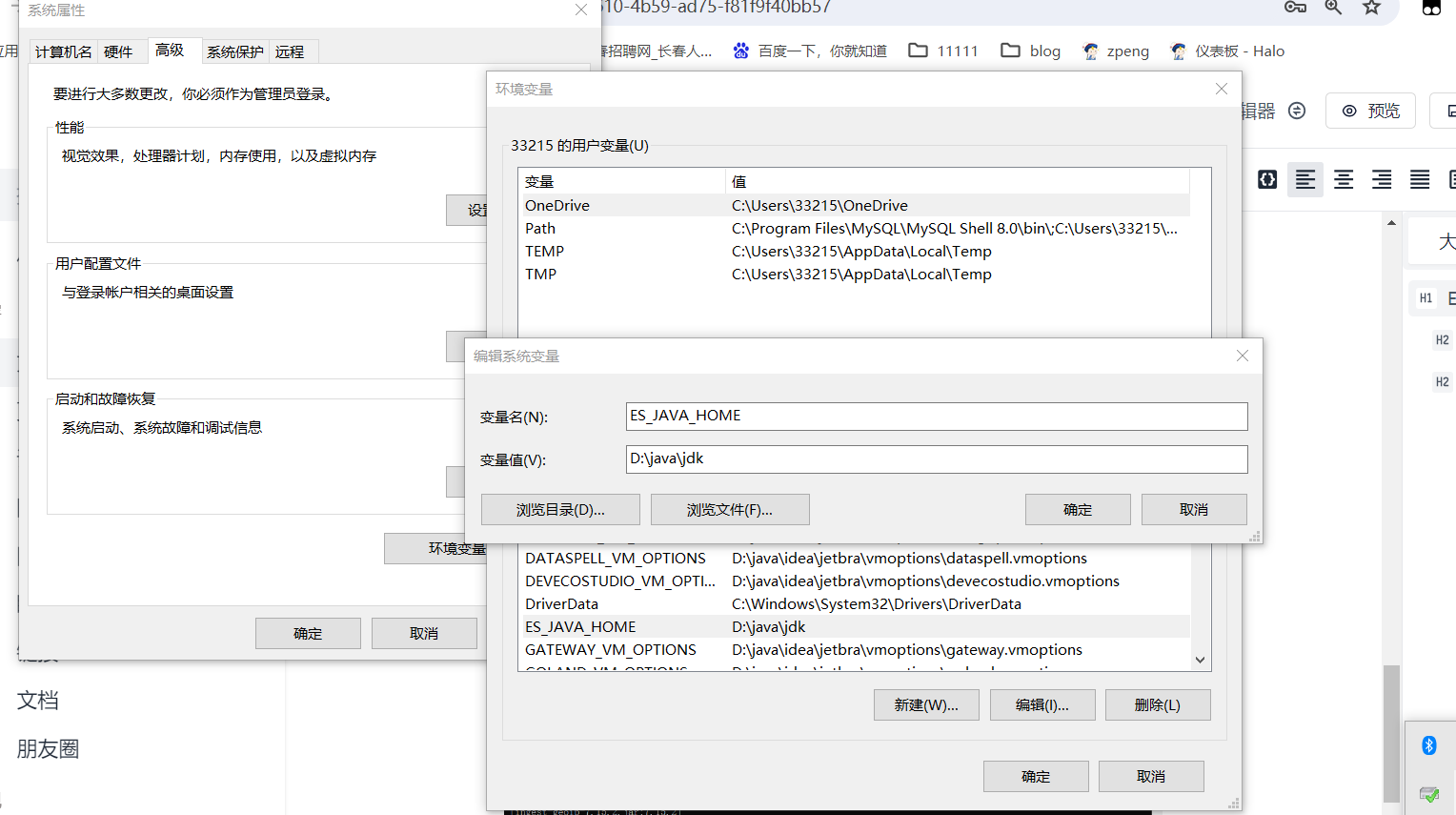 新建环境变量:
新建环境变量:
变量名:ES_JAVA_HOME
变量值(jdk目录):D:\java\jdk
这时可能会存在一个问题,用localhost可以访问到,用ip访问不到
需要修改Elasticsearch安装目录下的/config/elasticsearch.yml,在58行添加如下设置
network.bind_host: 0.0.0.0
6.下载安装Kibana
简介
Kibana是一个开源的分析与可视化平台,设计出来用于和Elasticsearch一起使用的。你可以用kibana搜索、查看存放在Elasticsearch中的数据。Kibana与Elasticsearch的交互方式是各种不同的图表、表格、地图等,直观的展示数据,从而达到高级的数据分析与可视化的目的。
Elasticsearch、Logstash和Kibana这三个技术就是我们常说的ELK技术栈,可以说这三个技术的组合是大数据领域中一个很巧妙的设计。一种很典型的MVC思想,模型持久层,视图层和控制层。Logstash担任控制层的角色,负责搜集和过滤数据。Elasticsearch担任数据持久层的角色,负责储存数据。而我们这章的主题Kibana担任视图层角色,拥有各种维度的查询和分析,并使用图形化的界面展示存放在Elasticsearch中的数据。
便于通过rest api调试ES。
版本选择
https://www.elastic.co/cn/support/matrix#matrix_compatibility
在使用Kibana时,需要注意Kibana的版本号必须和ES的版本相互对应,不然会出现Kibana和ES不兼容的问题,导致Kibana安装后不能使用
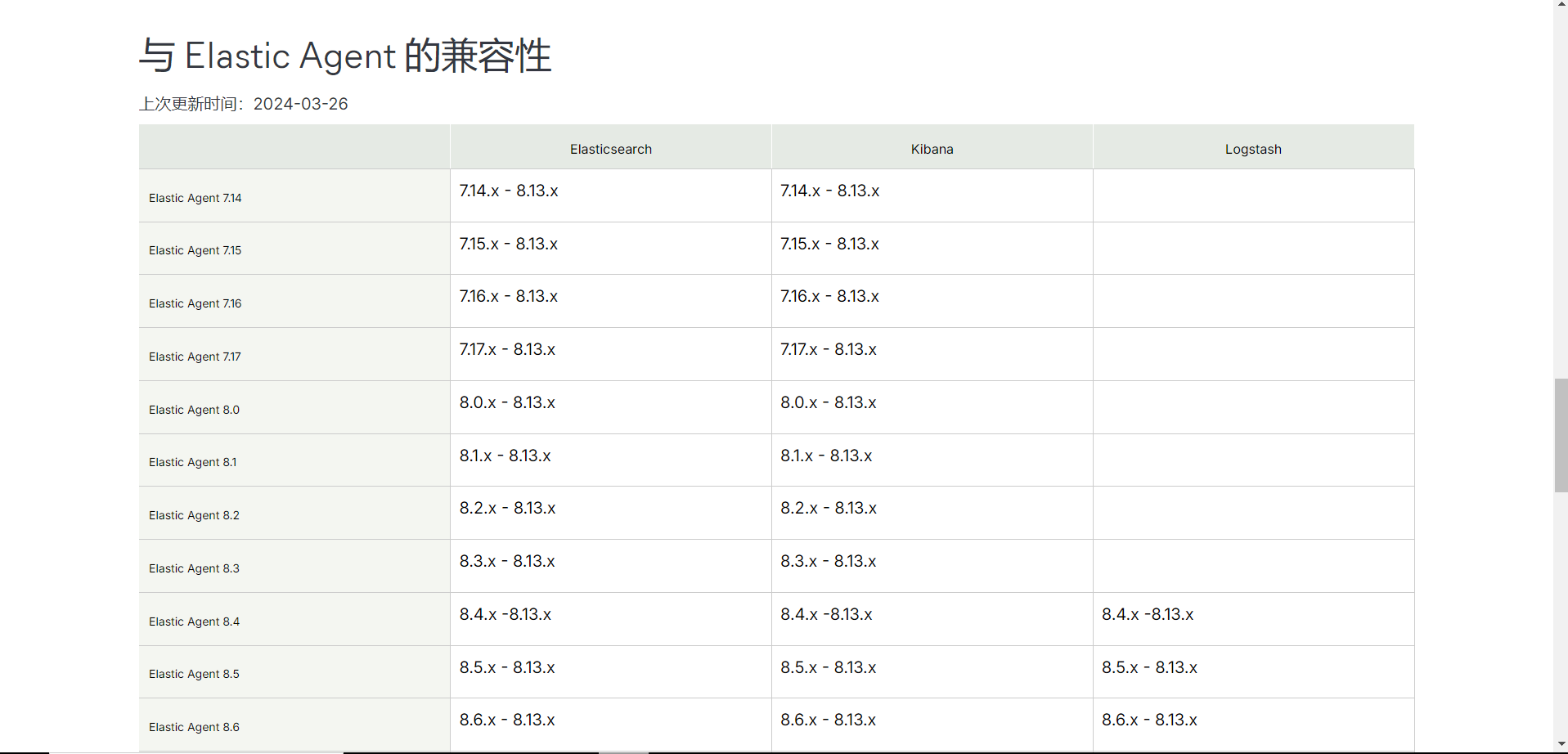
https://www.elastic.co/cn/downloads/past-releases/kibana-7-15-2
启动步骤
解压
修改 kibana-7.12.0-windows-x86_64/config/kibana.yml 32行
改为elasticsearch.hosts: [“http://127.0.0.1:9200”]
保存之后,运行bin/kibana.bat
浏览器中访问kibana首页首页链接
 http://127.0.0.1:5601/app/home#/
http://127.0.0.1:5601/app/home#/
 http://127.0.0.1:5601/app/dev_tools#/console
http://127.0.0.1:5601/app/dev_tools#/console
出现问题
如果想使用ip访问kibana,需要修改 kibana-7.12.0-windows-x86_64/config/kibana.yml 7行
改为 server.host: “0.0.0.0”
如果想使用kibana汉化 需要修改 kibana-7.12.0-windows-x86_64/config/kibana.yml 最后一行
i18n.locale: “zh-CN”
7.下载安装ik分词器
简介
什么是IK分词器 ?
分词:即把一段中文或者别的划分成一个个的关键字,我们在搜索时候会把自己的信息进行分词,会把数据库中或者索引库中的数据进行分词,然后进行一个匹配操作,默认的中文分词是将每个字看成一个词,比如“我爱狂神"会被分为"我"“爱”“狂"神”,这显然是不符合要求的,所以我们需要安装中文分词器ik来解决这个问题。
注意事项:
如果要使用中文,建议使用ik分词器 !
ik提供了两个分词算法:ik_smat 和ik_max_word,其中 ik_mart 为最少切分,ik_max_word为最细粒度划分!一会我们测试!
常用配置文件:
IKAnalyzer.cfg.xml:用来配置自定义词库。
main.dic:ik原生内置的中文词库,总共有27万多条,只要是这些单词,都会被分在一起,最常用的文件。
quantifier.dic:存放了一些单位相关的词。
suffix.dic:存放了一些后缀。
surname.dic:中国的姓氏。
stopword.dic:包含了英文的停用词,停用词 stop word ,比如 a 、the 、and、 at 、but 等会在分词的时候直接被干掉,不会建立在倒排索引中。
安装
注意:下载的ik分词器版本号要和安装的elasticsearch版本一致
把下载的ik分词器解压至Elasticsearch的安装目录/plugins/ik内。
重启elasticsearch
重启kibana
进入kibana的开发工具中执行命令
测试ik分词器
测试
ik_max_word最小粒度划分,穷尽所有组合,会出现重复的字。
ik_smart为最少切分,是将一句话按段切分出来的,分出来的内容没有重复的字。
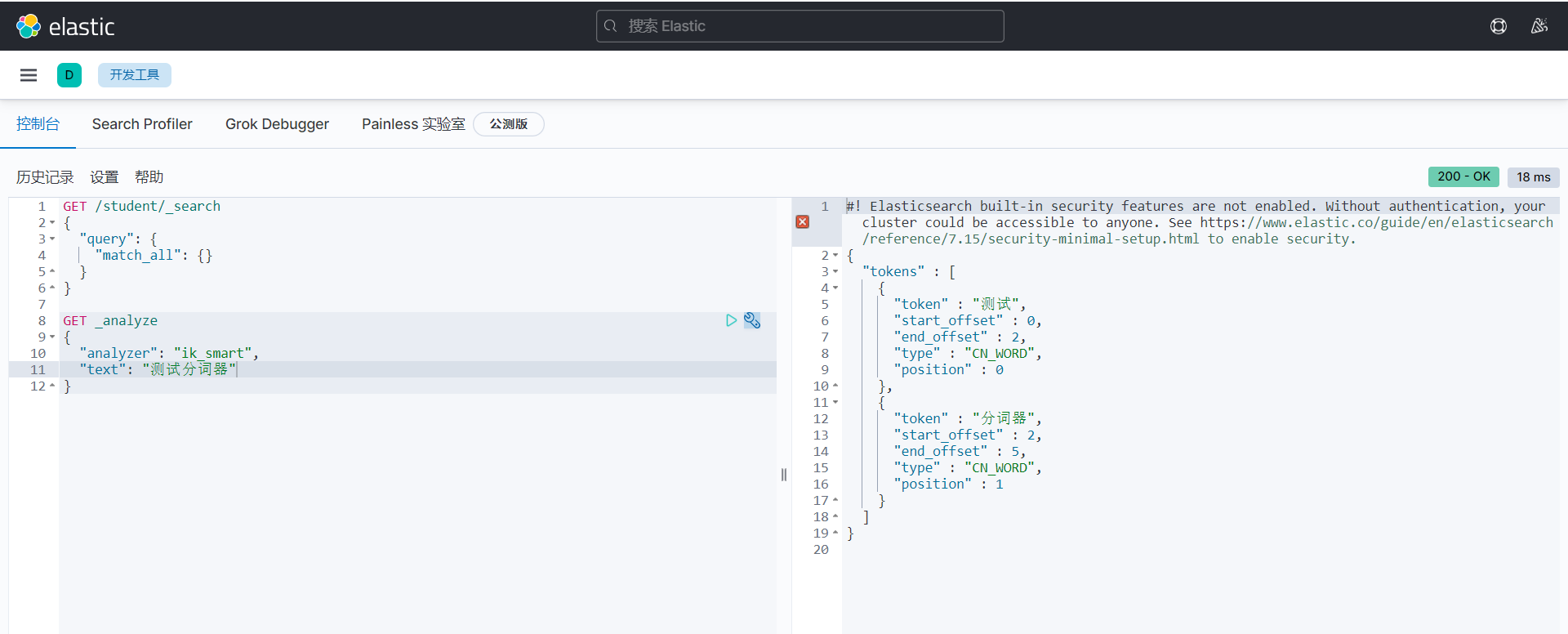
GET _analyze
{
"analyzer": "ik_max_word",
"text": "测试分词器"
}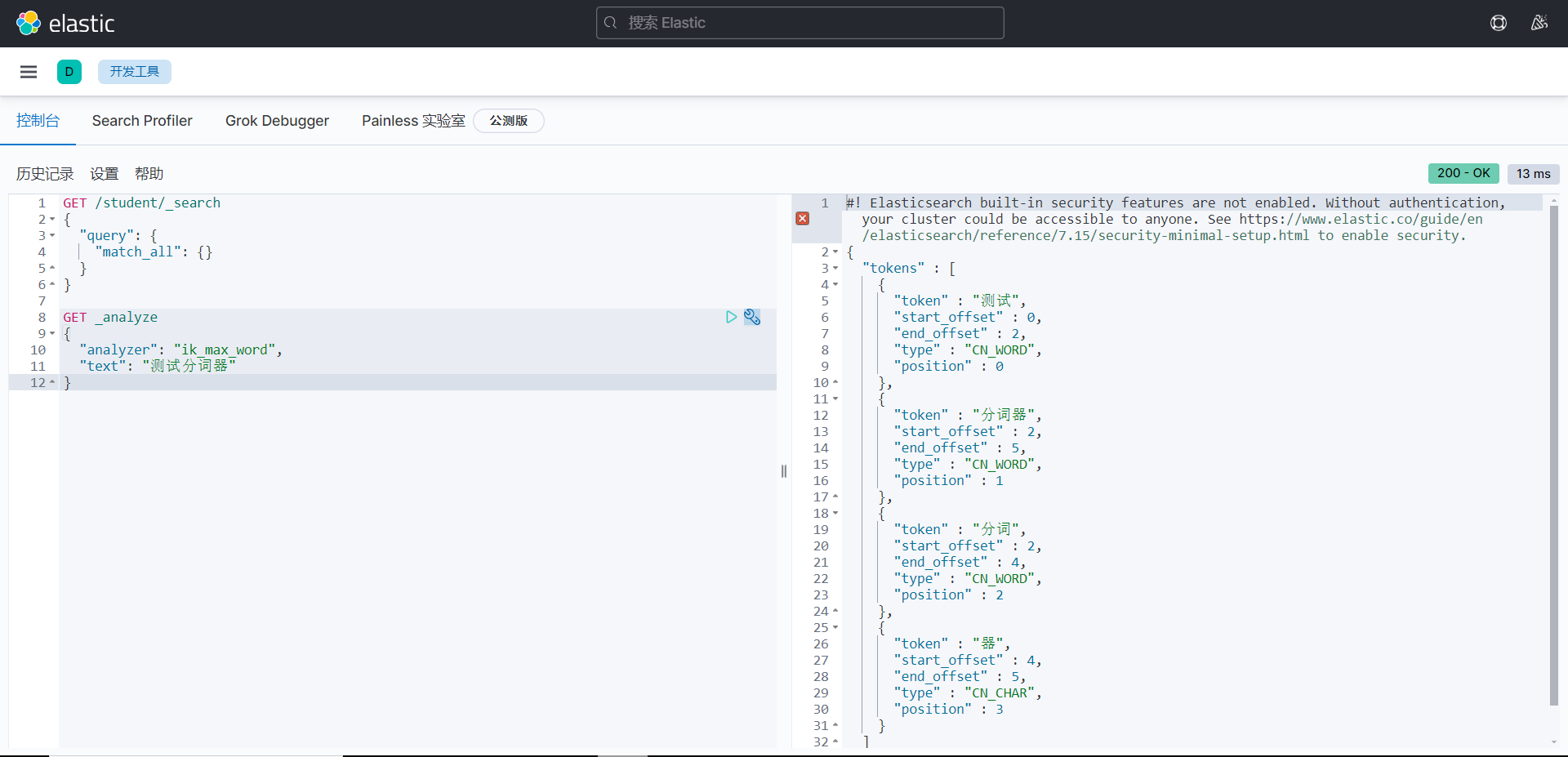
#! Elasticsearch built-in security features are not enabled. Without authentication, your cluster could be accessible to anyone. See https://www.elastic.co/guide/en/elasticsearch/reference/7.15/security-minimal-setup.html to enable security.
{
"tokens" : [
{
"token" : "测试",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "分词器",
"start_offset" : 2,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "分词",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "器",
"start_offset" : 4,
"end_offset" : 5,
"type" : "CN_CHAR",
"position" : 3
}
]
}
#! Elasticsearch built-in security features are not enabled. Without authentication, your cluster could be accessible to anyone. See https://www.elastic.co/guide/en/elasticsearch/reference/7.15/security-minimal-setup.html to enable security.
{
"tokens" : [
{
"token" : "测试",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "分词器",
"start_offset" : 2,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 1
}
]
}
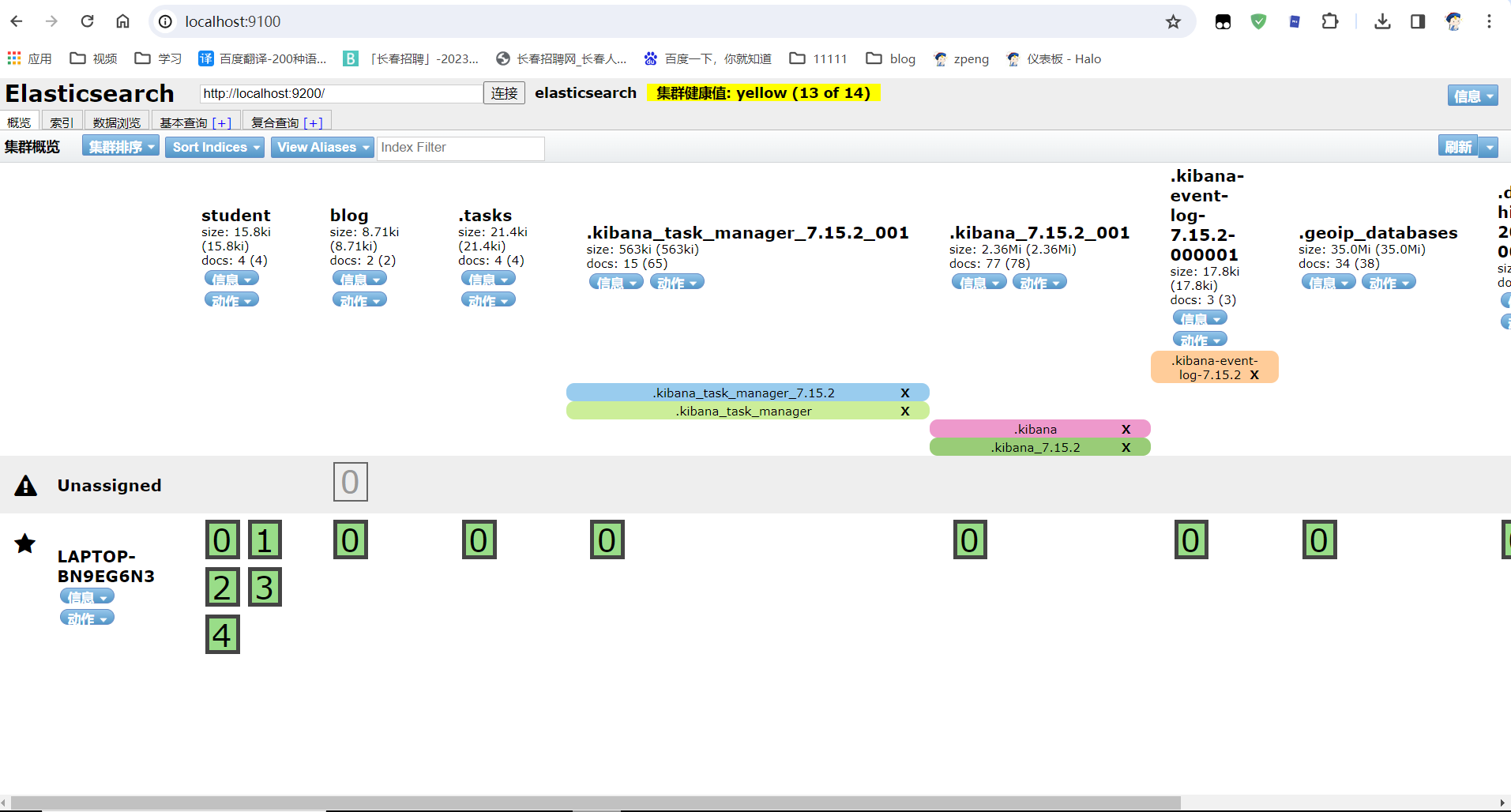
8.下载安装es-head插件
Google浏览器插件 安装Google浏览器插件,直接访问Elasticsearch
npm安装 下载源码,编译安装,在nodejs环境下运行插件
简介
es-head插件在0.x-2.x版本时,是集成在elasticsearch内的。由elasticsearch的bin/elasticsearch-plugin来管理插件,从2.x版本跳到了5.x版本后,head就作用了一个独立的服务来运行了。
Elasticsearch 5之后则需要将elasticsearch-head服务单独运行,并且支持Chrome的插件方式或者Docker容器运行方式。
插件简介:
Head 插件,全称为 elasticsearch-head,是一个界面化的集群操作和管理工具,可以对集群进行“傻瓜式”操作。
既可以把 Head 插件集成到 Elasticsearch 中,也可以把 Head 插件当成-个独立服务。
主要功能:
显示es集群的拓扑结构,能够执行索引和节点级别的操作。
在搜索接口能够查询es集群中原始JSON 或表格格式的数据。
能够快速访问并显示es集群的状态。
安装
安装node.js环境,注意版本不要太高,不然会跟linux本身的依赖库包版本冲突报错。使用命令:node -v。
git clone git://github.com/mobz/elasticsearch-head.gitcd elasticsearch-headnpm installnpm run start
问题
没有显示数据
修改es配置文件,添加如下两行,解决跨域问题
[root@localhost elasticsearch-8.5.2]# vi config/elasticsearch.yml
http.cors.enabled: true
http.cors.allow-origin: "*"
http.cors.enabled: true
http.cors.allow-origin: "*"
http.cors.allow-credentials: true
http.cors.allow-headers: Content-Type,Accept,Authorization,x-requested-with
#http.cors.allow-headers: "*"
使用