



C语言基础
本文最后更新于 2024-03-23,欢迎来到我的Blog! https://www.zpeng.site/
1.1.变量定义
#include <stdio.h>
/*
* 定义变量,变量的名字是a,类型是int。
* 没有赋值,初始值是0!
*/
int main() {
int a;
printf("a = %d", a); // a = 0
}变量的名字(标识符):
只能由字母、数字、下划线组成。
数字不可以出现在第一个位置上。
C语言的关键字不能做标识符。
1.2.变量输入
#include <stdio.h>
int main() {
int price = 0;
printf("请输入金额(元):");
scanf("%d", &price);
int change = 100 - price;
printf("找您%d元。\n", change);
return 0;
}如果在scanf中不是输入整数,而是输入字符串呢??
请输入金额(元):hello
找您100元。 # why?这里居然输出的是100!
--------------------------------
Process exited after 3.814 seconds with return value 0
请按任意键继续. . .1.3.浮点数
#include <stdio.h>
int main() {
printf("%d\n", 10/3); // 3 小数部分直接舍去
printf("%d\n", 14/3); // 4 小数部分直接舍去
printf("%d\n", 10/3*3); // 9
printf("%f\n", 10.0/3); // 3.333333
printf("%f\n", 10.0/3*3); // 10.000000
return 0;
}浮点数:指带小数点的数值。人们借用浮点数这个词来表达所有的带小数点的数。
当浮点数和整数放到一起运算时,C语言会将整数转换为浮点数,然后进行浮点数的运算。
double表示双精度浮点数,%lf;float表示单精度浮点数,%f。
1.4.运算符优先级
优先级从高到底排列
一般来说运算符都是自左向右运算;
但是单目运算符+-和赋值运算符=是自右向左运算。
#include <stdio.h>
int main() {
int c = 5;
int a;
int b;
int result = a = b = 3 + c;
result = 2;
result = (result = result * 2) * 6 * (result = 3 + result); // 这种表达式不要写
printf("a = %d\n", a); // 8
printf("b = %d\n", b); // 8
printf("c = %d\n", c); // 5
printf("result = %d\n", result); // 168
}1.5.复合赋值
5个算数运算符,
+ - * / %可以和赋值运算符=结合起来,形成复合赋值运算符;total += 5;total = total + 5;注意两个运算符中间不要有空格!
1.6.递增递减运算符
++和--是两个很特殊的运算符,他们是单目运算符,这个算子必须是变量。作用就是给变量
+1或者-1。
前缀和后缀
#include <stdio.h>
int main() {
int a = 10;
printf("a++ = %d\n", a++); // 10
printf("a = %d\n", a); // 11
printf("++a = %d\n", ++a); // 12
printf("a = %d\n", a); // 12
return 0;
} 1.7.多路分支
switch-case基本语法
switch(控制表达式) {
case 常量:
语句
...
break;
case 常量:
语句
...
break;
default:
语句
...
break;
} 控制表达式只能是整数型的结果;
常量可以是常数,也可以是常数计算的表达式;
switch-case来描述分段函数
#include <stdio.h>
#include <math.h>
// 分段函数
int segment(int x) {
// 结果
int fx;
// 如果x=0就直接结束
if(x == 0) {
return 0;
}
// 自己和绝对值相除
int type = x/abs(x);
switch(type) {
case 1:
fx = 2 * x;
break;
case -1:
fx = -1;
break;
}
return fx;
}
int main() {
int x;
scanf("%d", &x);
printf("f(%d) = %d", x, segment(x));
return 0;
}1.8.级联判断
#include <stdio.h>
/**
* if-else if-else 级联的判断
* 这种大于的适合从上向下判断
*/
int method1(int x) {
int n;
if(x > 999) {
n = 4;
} else if(x > 99) {
n = 3;
} else if(x > 9) {
n = 2;
} else {
n = 1;
}
return n;
}
int main() {
int x;
scanf("%d", &x);
printf("method1(%d) = %d\n", x, method1(x));
return 0;
}2.数据类型
2.1.C语言的类型
2.1.1.常见类型
整数:
char、short、int、long、long long。浮点数:
float、double、long double。逻辑:
bool。指针。
自定义类型。
其中long long、long double、bool是C99的类型。
2.1.2.sizeof()
sizeof()是一个运算符,给出某个类型或者变量在内存中所占的字节数。
#include <stdio.h>
int main() {
// C语言里没有byte
printf("sizeof(short) = %d\n", sizeof(short)); // 2
printf("sizeof(int) = %d\n", sizeof(int)); // 4
printf("sizeof(long) = %d\n", sizeof(long)); // 4
printf("sizeof(float) = %d\n", sizeof(float)); // 4
printf("sizeof(double) = %d\n", sizeof(double)); // 8
printf("sizeof(bool) = %d\n", sizeof(bool)); // 1
printf("sizeof(char) = %d\n", sizeof(char)); // 1
return 0;
}sizeof()是静态运算符,它的结果在编译时刻就决定了。
不要在sizeof()的括号里面做运算,这里运算是不会做的。
#include <stdio.h>
// sizeof()不会真的去做计算,只是将()内的数据类型计算出来即可
int main() {
int a = 6;
printf("sizeof(a) = %d\n", sizeof(++a)); // sizeof(a) = 4
printf("sizeof(a+1.0) = %d\n", sizeof(a+1.0)); // sizeof(a+1.0) = 8
printf("a = %d\n", a); // a = 6
return 0;
}2.2.整数类型
2.2.1.几种整数类型
#include <stdio.h>
int main() {
// C语言里没有byte
printf("sizeof(char) = %d\n", sizeof(char)); // 1
printf("sizeof(short) = %d\n", sizeof(short)); // 2
printf("sizeof(int) = %d\n", sizeof(int)); // 4
printf("sizeof(long) = %d\n", sizeof(long)); // 4(32位OS) 8(64位OS)
printf("sizeof(long long) = %d\n", sizeof(long long)); // 8
return 0;
}byte(字节) = 8bit(位)。
char:1字节。short:2字节。int:取决于编译器CPU,通常的意义是"1个字"。long:取决于编译器CPU,通常的意义是"1个字"。long long:8字节。
2.2.2整数的范围
负数的存在形式
#include <stdio.h>
int main(int argc, char const *argv[]) {
char i = -5;
char a = 129;
/**
* 如果确实是负数的话,计算机中存储的二进制数就是补码。
*
* 1111 1011 -> FB(计算机存储的2进制数)
* 1000 0101 -> (FB的源码,表示的是-5)
*/
printf("0x%hhX\n", (char)i); // 0xFB
/**
* 如果是超出正数范围的数,在计算机中存的二进制数就是原码,
* 但是要用有符号的数表示,就会输出补码的值(因为超出正数范围了)。
*
* 1000 0001 -> 81(计算机存储的2进制数)
* 1111 1111 -> (补码表示的是-127)
*/
printf("0x%hhX\n", a); // 0x81
printf("%d\n", a); // -127
printf("%u\n", (unsigned char)a); // 129
return 0;
}有符号数和无符号数的范围
对于一个字节(8位),可以表达的是00000000 ~ 11111111。
无符号数就是0 ~ 255,在计算机中表示整数范围是-128 ~ 127。
#include <stdio.h>
/*
* %d是有符号的输出整数
*
* char的范围 -128 ~ 127
* 1 1 1 1 1 1 1 1 ---> 无符号数代表255,其中二进制码第一个1代表负数,
* 在计算机中超过127的部分以补码形式存在,即:
* 1 0 0 0 0 0 0 1 ---> -1
*/
void rangOfChar() {
char c = 255;
int i = 255;
printf("c = %d\n", c); // -1
printf("i = %d\n", i); // 255
}
/**
* unsigned char 的范围 0 ~ 255
* 这是被当做纯二进制看待的,二进制码第1位不做符号位!
*/
void rangeOfUsignedChar() {
unsigned char c = 255;
printf("c = %d\n", c); // 255
}
int main() {
rangOfChar();
rangeOfUsignedChar();
return 0;
}如果一个字面量常数想要表达自己是unsigned,可以在后面加u/U。
用l/L来表示long。
unsigned的初衷并非为了扩展正数的表达范围,而是为了做纯二进制计算,主要是为了移位。
// 例如
unsigned char c = 255U;
long a = 1000L;整数越界
整数是以纯二进制方式进行计算的。
# 以1个字节(8位)为例子
# 1、本来是8位多出来一位,就将最高位的1舍去
1111 1111 + 1 ---> 1 0000 0000 ---> 0(十进制)
# 2、+1之后最高位是1,就是负数,补码还是1000 0000,所以十进制数就是-128
0111 1111 + 1 ---> 1000 0000 ---> -128(十进制)
# 3、-1 <=> +(-1)
# -1: 源码:1000 0001
# 补码:1111 1111
# 用补码去参加计算:1000 0000(-128补) + 1111 1111(-1补) = 0111 1111(127)
1000 0000 - 1 ---> 1000 0000 + (-1) ---> 1000 0000 + 1111 1111(-1的补码) ---> 0111 1111 ---> 127(十进制)
计算unsigned的范围???
#include <stdio.h>
/**
* %u是无符号整数输出;
* 1111 1111 表示无符号整数255,当+1的时候就会变成1 0000 0000(十进制0);
* 0000 0000 - 1 ---> 0000 0000 + 1111 1111(-1的补码) ---> 1111 1111;
* 这时候用%u无符号整数输出即可;
* 但是要注意 char 和 int 做计算会将char转成int,这里需要类型转换。
*/
void rangeOfUnsignedChar() {
unsigned char c = 0;
while(++c > 0);
printf("c = %u\n", (unsigned char)(c - 1)); // 255
}
void rangeOfUnsignedInteger() {
unsigned int i = 0;
while(++i > 0);
printf("i = %u\n", i - 1); // 4294967295
}
int main() {
rangeOfUnsignedChar();
rangeOfUnsignedInteger();
return 0;
}2.2.3.整数的格式化
输入输出格式
%d: int,有符号整数;%u: unsigned int,无符号整数;%ld:long long;%lu: unsigned long long。
#include <stdio.h>
/**
* %u 和 %d 输出的就是十进制整数 32位二进制数,不够32的位输出的会补足32位!
*
* 1000 0001 ---> -1
* (1)当以%d输出的时候char的范围是 -128 ~ 127,显然没有发生越界,
* 则就是以1000 0001输出,结果就是-1。
* (2)当以%u输出的时候char的范围是 0 ~ 255,不包括-1,显然发生越界了,
* 1000 0001(原码) ---> 1111 1111(补码),负数就会以补码形式输出!
*/
void format() {
char c = -1;
int i = -1;
printf("c = %d\n", c); // -1
printf("i = %d\n", i); // -1
printf("c = %u\n", (unsigned char)c); // 255
printf("c = %u\n", c); // 4294967295
printf("i = %u\n", i); // 4294967295
}
int main() {
format();
return 0;
}8进制和16进制
以
0开始的数字字面量是8进制。以
0x开始的数字字面量是16进制。%o用于输入输出8进制,%x用于输入输出16进制。8进制和16进制数字与计算机内部如何表达无关,计算机内部都是二进制。
#include <stdio.h>
/**
* 我们看的时候是有8进制,10进制,16进制,在计算机中永远是2进制,
* 输入的数字在计算机中都会被转成2进制!
*/
void OtcAndHex() {
char c = 012;
int i = 0x12;
// 输出十进制用 %d (decimal)
printf("c = %d\n", c); // 10
printf("i = %d\n", i); // 18
// 输出8进制用 %o (octal)
printf("c = 0%o\n", c);
// 输出16进制用 %x (Hex)
printf("i = 0x%x\n", i);
}
int main() {
OtcAndHex();
return 0;
}2.2.4.选择整数类型
没有特殊需要,就选择int:
现在的CPU的字长普遍就是32位或者64位,一次读写就是一个
int,一次计算也是一个int,选择更短的类型不会更快,甚至可能更慢!线代的编译器一般会设计内存对齐,所以更短的类型实际在内存中有可能也占据一个
int的大小(虽然sizeof()告诉你更小)。
unsigned是否使用只是输出结果的不同,内部计算是一样的,不是迫不得已,没有必要用!
2.3.浮点类型
2.3.1.几种浮点类型

浮点数的范围:
靠近0的一小部分区域是不能表示的。
0可以用浮点数来表示。
±inf正负无穷可以用浮点数来表示。nan代表不是一个有效的数字,浮点数可以表示。

浮点的输入输出
#include <stdio.h>
/**
* 浮点数可以用科学计数法来表达
* %.16f 可以指定保留小数点后16位小数
*/
void useE() {
double d = 1234.56789;
double d1 = 1E-10;
printf("d = %e\n", d); // d = 1.234568e+003
printf("d = %E\n", d); // d = 1.234568E+003
printf("d = %f\n", d); // d = 1234.567890
printf("d1 = %f\n", d1); // d1 = 0.000000
printf("d1 = %.16f\n", d1); // d1 = 0.0000000001000000
// 保留小数点后几位是有四舍五入的!
printf("%.3f\n", -0.0049); // -0.005
// -0.004899999999999999800000000000
// 浮点数是有误差的!
printf("%.30f\n", -0.0049);
printf("%.3f\n", -0.00049); // -0.000
}
int main() {
useE();
return 0;
}2.3.2.浮点数的范围
浮点数的范围
#include <stdio.h>
/**
* 浮点数可以表示正负无穷和不存在的数
*/
void rangeOfFloat() {
//printf("%d\n", 12/0); // 编译报错
printf("%f\n", 12.0/0.0); // 1.#INF00
printf("%f\n", -12.0/0.0); // -1.#INF00
printf("%f\n", 0.0/0.0); // -1.#IND00
}
int main() {
rangeOfFloat();
return 0;
}浮点数的计算是有误差的!
#include <stdio.h>
/**
* 浮点数的运算:有误差
*
* 输出结果:
* 不相等!c = 2.4679999352, c = 2.468000
*/
void calculateOfFloat() {
float a, b, c;
a = 1.345f; // 使用f来代表float,不写就代表double
b = 1.123f;
c = a + b;
if(c == 2.468) {
printf("相等\n");
} else {
printf("不相等!c = %.10f, c = %f\n", c, c);
}
}
int main() {
calculateOfFloat();
return 0;
}2.3.3.选择浮点数
如果没有特别需要,只使用
double。现在的CPU能直接对
double做硬件计算,性能不会比float差,在64的机器上,数据存储的速度也不会比float慢。
2.4.字符类型
2.4.1.char???
char是整数,也是一种特殊的类型,字符类型:
用单引号表示字符的字面量:
'a'、'i'。' '也是一个字符。printf()、scanf()里用%c来输入输出字符。
#include <stdio.h>
/**
* 字符类型
*
* char有两种形式:整数形式 和 字符形式。
* 在计算机内部 字符 '1' <==> 49 都是代表的同一个值!
* 所以,我们可以给 char 变量赋值字符,也可以赋值整数!
*/
void typeOfChar() {
char c;
char d;
c = 1; // 整数
d = '1'; // 字符类型
if(c == d) {
printf("相等\n");
} else {
printf("不相等\n");
printf("c = %d\n", c); // 1
printf("d = %d\n", d); // 49 计算机内部用整数49来表示'1'
}
}
/**
* 字符类型的输入和输出
*/
void inputChar() {
char a;
scanf("%c", &a); // 字符的输入 t
printf("a = %c\n", a); // 作为字符输出 a = t
printf("a = %d\n", a); // 作为整数输出 a = 116
}
int main() {
inputChar();
typeOfChar();
return 0;
}2.4.2.混合输入
scanf("%d %c", &i, &c); scanf("%d%c", &i, &c);有什么区别????
#include <stdio.h>
/**
* 混合输入1
*********************************
* 输入: 12 1
* 输出:
* i = 12
* c = '1'
* c = 49
*********************************
* 输入: 12t
* 输出:
* i = 12
* c = 't'
* c = 116
*********************************
* 输入: 12 1
* 输出:
* i = 12
* c = '1'
* c = 49
*********************************
*/
void mixInput1() {
int i;
char c;
scanf("%d %c", &i, &c);
printf("i = %d\n", i);
printf("c = '%c'\n", c);
printf("c = %d\n", c);
}
/**
* 混合输入2
*********************************
* 输入: 12 1
* 输出:
* i = 12
* c = ' '
* c = 32
*********************************
* 输入: 12t
* 输出:
* i = 12
* c = 't'
* c = 116
*********************************
* 输入: 12 1
* 输出:
* i = 12
* c = ' '
* c = 32
*********************************
*/
void mixInput2() {
int i;
char c;
scanf("%d%c", &i, &c);
printf("i = %d\n", i);
printf("c = '%c'\n", c);
printf("c = %d\n", c);
}
int main() {
mixInput1();
mixInput2();
return 0;
}2.4.3.字符计算
#include <stdio.h>
int main() {
char c = 'A';
c++;
printf("c = %c\n", c); // c = B
int i = 'Z' - 'A';
printf("i = %d\n", i); // i = 25
return 0;
}一个字符加一个数字得到ASCII码表中那个数之后的字符。
两个字符相减,得到他们在表中的距离。
2.4.4.大小写转换
大写字母在ASCII表中是顺序排列的。
大写字母和小写字母是分开排列的,并不在一起。
'a' - 'A'可以得到两段之间的距离,所以a + 'a' - 'A':大写 => 小写。a + 'A' - 'a':小写 => 大写。
#include <stdio.h>
int main() {
char a = 'a';
a += 'A' - 'a'; // 小写 => 大写
printf("a = '%c'\n", a); // a = 'A'
a += 'a' - 'A'; // 大写 => 小写
printf("a = '%c'\n", a); // a = 'a'
return 0;
}2.5.转义字符
转义字符:用来表达无法打印出来的控制字符或者特殊字符,由一个反斜杠\开头,后面跟上一个字符,这两个字符组合起来,组成了一个字符。
# 1、所有的ASCII码都可以用"\"加数字(一般是八进制数字)来表示。
# 2、而C中定义了一些字母前加"\"来表示常见的那些不能显示的ASCII字符,如\0,\t,\n等,就成为转义字符,因为后面的字符,都不是它本来ASCII字符的意思了。# 字符型常量
# 1、C语言中字符型常量所表示的值是int型所能包含的值。我们可以用ASCII表达式来表示一个字符型常量,或者用单引号内加反斜杠表示转义字符。'A', '\x2f', '\013';
# 2、其中:\x表示后面的字符是十六进制数,\0表示后面的字符是八进制数。例如十进制的17用十六进制表示就是 ‘\x11’,用八进制表示就是‘\021’;
# 3、上面我们见到的\x,\n,\a等等都是叫转义字符,它告诉编译器需要用特殊的方式进行处理。#include <stdio.h>
/**
* /b(回退一格):通常是回去但不删除;
* 输出:
* 12A
* 456
*/
int main() {
printf("123\bA\n456");
return 0;
}2.6.类型转换
自动类型转换
char -> short -> int -> long -> long long。int -> float -> double。对于
printf,任何小于int的类型会被转换成int;float会被转换成double。但是
scanf不会自动转换,要输入short,需要%hd。
强制类型转换
把一个量强制转换成另一个类型(通常是较小的类型),需要:
语法:(类型)值。
(int)10.2、(short)32。注意:这时候的安全性,表的变量不能总是表达大的变量。
short的范围是-32768 ~ 32767,当(short)32768的时候,就会出现问题。
#include <stdio.h>
int main() {
printf("%d\n", 32768); // 32768
// short范围 -32768 ~ 32767 发生越界了
printf("%d\n", (short)32768); // 32768
return 0;
} 强制类型转换只是算出了一个新的值,原来值的不会有任何的改变。
#include <stdio.h>
int main() {
int i = 32768;
short s = (short)i;
printf("i = %d\n", i); // 32768
printf("s = %d\n", s); // -32768
return 0;
}强制类型转换的优先级高于四则运算。
#include <stdio.h>
int main() {
double a = 1.0;
double b = 2.0;
/**
* int i = (int )a / b; 是将a做了强制类型转换
*/
int i = (int)(a / b);
printf("i = %d\n", i);
}2.7.逻辑运算
逻辑运算是対逻辑量进行的运算,结果只有0或者1。
逻辑量是关系运算或者逻辑运算的结果。
如何判断一个字符是否是大写字母?
// 判断字符是否是大写字母
void isUppercase(char c) {
if(c >= 'A' && c <= 'Z')
printf("'%c'是大写字母!", c);
else
printf("'%c'不是是大写字母!", c);
}逻辑运算简单应用
age > 20 && age < 30 # 20 < age < 30
index < 0 || index > 99 # 小于0或大于99
!age < 20 # !age会先做运算,所以!age不是0就是1,整个表达式结果永远都是12.7.1.运算符优先级(全)
! > && > ||。例如!done && (count > MAX)。
运算符由高到低
赋值运算优先级永远是最低的!
单目运算优先级很高,
!就是单目运算。
https://jingyan.baidu.com/article/ae97a646c865ccbbfd461dd3.html
2.7.2.逻辑运算短路
逻辑运算是自左向右进行的,如果左边的结果已经能够决定结果了,就不会做右边的计算。
a==6 && b==1a==6 && b+=1对于
&&,左边是false时就不会计算右边了!对于
||,左边是true时就不会计算右边了!
// 不要把赋值(组合赋值)写进条件表达式!
void logicOperation() {
int i = -1;
if(i > 0 && ++i > 1) {
printf("OK!\n");
}
printf("i = %d\n", i); // i = -1
}3.函数
3.1.函数原型声明
#include <stdio.h>
// 将函数写在下面,需要事先声明,才可以调用
// 这里叫做函数的原型声明(不是函数)
void sum(int, int);
int main() {
sum(1, 2);
sum(3, 5);
return 0;
}
// 这里叫做函数的定义
void sum(int a, int b) {
printf("%d + %d = %d\n", a, b, a+b);
}3.2.参数传递
3.2.1.可以传递的参数
如果函数有参数,调用函数时必须传递给它数量、类型正确的值。
可以传递给函数的值是表达式的结果,这包括:
字面量。
变量。
函数的返回值。
计算的结果。
int a, b, c;
a = 5;
b = 6;
c = max(10, 12);
c = max(a, b);
c = max(c, 23);
c = max(max(23, 45,), a);
c = max(23+45, b);3.2.2.参数类型不匹配?
调用函数时给的值与参数的类型不匹配是C语言传统上最大漏洞。
编译器总是悄悄帮你把类型转换好,但是这很可能不是你所期望的。
后续的语言,C++ Java在这方面很严格。
#include <stdio.h>
void cheer(int i) {
printf("cheer %d\n", i); // 2
}
int main() {
cheer(2.4); // 参数类型不匹配, 会发生强制类型转换
return 0;
}3.2.3.传参传的是什么?
传值!传值!!传值!!!
C语言在调用函数时,永远只能传值给函数。
#include <stdio.h>
/**
* C语言在调用函数的时候,永远是传值给函数!
* 在函数中做的任何操作,和main()中的a, b没有关系!
* 这样的代码不能交换a, b的值!
*/
void swap(int a, int b) {
int temp = a;
a = b;
b = temp;
}
int main() {
int a = 1, b = 2;
swap(1, 2);
printf("a = %d\n", a); // a = 1
printf("b = %d\n", b); // b = 2
return 0;
}3.3.本地变量
什么是本地变量?
函数的每次运行,就产生了一个独立的变量空间,在这个空间中的变量,是函数的这次运行所独有的,称作本地变量。
定义在函数内部的变量就叫做本地变量。
函数的参数列表也是本地变量。
变量的生存期和作用域
生存期:什么时候这个变量开始出现了,到什么时候它消亡了?
作用域:在(代码的)什么范围内可以访问这个变量(这个变量可以起什么作用)?
对于本地变量,以上两个问题的答案是统一的:大括号内——块。
本地变量的规则
本地变量是定义在块内的。
它可以是定义在函数的块内。
也可以定义在语句的块内。
甚至可以随便拉一对大括号来定义变量。
程序运行进入这个块之前,其中的变量不存在,离开这个块,其中的变量就消失了。
块外面定义的变量在块内仍然有效。
块里面定义了和外面同名的变量则掩盖了外面的。
本地变量不会被默认初始化。
参数在进入函数的时候被初始化了。
#include <stdio.h>
int main() {
// 定义在函数内的本地变量
int a = 1, b = 2;
if(a < b) {
// 定义在语句块内的本地变量
int i = 10;
}
// i++; // 编译就会报错
return 0;
}4.数组
4.1.数组的基本使用
定义数组
<type> name[length];元素的数量必须是整数。
int record[100]; // 定义数组,数组中每一个元素都是int类型什么是数组?
数组是一种容器,特点是:
其中所有的元素具有相同的数据类型;
一旦创建,不能改变大小;
数组中的元素在内存中是连续依次排列的。
数组的例子
#include <stdio.h>
/**
* 输入数量不确定的[0,9]范围内的整数,
* 统计每一种数字出现的次数,-1表示结束。
*/
int main() {
const int LEN = 10;
int record[LEN] = {0}; // 数组的初始化全部清零
int x;
printf("请输入[0,9]的数(-1表示结束):\n");
do {
scanf("%d", &x);
if(x>=0 && x<=9) {
record[x]++;
}
} while(x != -1);
for(int i = 0; i < LEN; i++) {
printf("输入%d的次数是: %d\n", i, record[i]);
}
return 0;
}4.2.数组运算
4.2.1.数组大小
sizeof()给出整个数组所占的内容的大小,单位是字节。
#include <stdio.h>
int main() {
int a[10];
// sizeof(a) = 40
printf("sizeof(a) = %d\n", sizeof(a));
// a.length = sizeof(a)/sizeof(a[0]) = 10
printf("a.length = sizeof(a)/sizeof(a[0]) = %d", sizeof(a)/sizeof(a[0]));
return 0;
}4.2.2.数组的赋值
int a[] = {1,2,3,4,5,6,7,8,9};
// int b[] = a[]; // 错误!不可以!数组变量本身不能被赋值。
要把一个数组的所有元素交给另一个数组,必须采用遍历。
数组作为函数的参数时,需要另一个参数来传入数组的大小!

4.3.二维数组
二维数组的初始化
#include <stdio.h>
int main() {
// 定义二位数组,行可以不写,列必须写出来
int a[][6] = {
{0, 1, 2, 3, 4, 5},
{2, 3, 4, 5, 6, 7}
};
int rows = sizeof(a)/sizeof(a[0]); // 二维数组的行
int cols = sizeof(a[0])/sizeof(a[0][0]); // 二位数组的列
// 二维数组的遍历
for(int i=0; i<rows; i++) {
for(int j=0; j<cols; j++) {
printf("%d", a[i][j]);
if(j < cols-1) {
printf("\t");
}
}
printf("\n");
}
return 0;
}二维数组的取地址
#include <stdio.h>
#define ROWS 8
#define COLS 9
/**
* a[m][n] = *(base_add + m * COLS + n);
* 二维数组的话在内存中也是连续的!第一行最后一个元素和第二行第一个元素地址只差一个sizeof(type)
* 通过上述式子就能表示为什么数组可以定义为a[][COLS]了!
*
* 至于为什么数组的下标从0开始?
* 0就代表了地址的偏移量,首先需要一个起始地址base_add,当我们访问数组第一个元素时,
* 地址的偏移量就是0,即式子中的m是0,所以数组下标是从0开始的。
*/
int main(int argc, char const *argv[]) {
int a[ROWS][COLS];
for(int i = 0; i < ROWS; i++) {
for(int j = 0; j < COLS; j++) {
a[i][j] = i + j;
}
}
printf("---------------------------------------\n");
for(int i = 0; i < ROWS; i++) {
for(int j = 0; j < COLS; j++) {
printf("%d\t", a[i][j]);
}
printf("\n");
}
printf("---------------------------------------\n");
for(int i = 0; i < ROWS; i++) {
for(int j = 0; j < COLS; j++) {
printf("%X\t", &a[i][j]);
}
printf("\n");
}
printf("---------------------------------------\n");
int *base_add = &a[0][0];
int m = 0; // 行
int n = 0; // 列
printf("请输入行和列:\n");
scanf("%d%d", &m, &n);
printf("a[%d][%d] = %d\n", m, n, *(base_add + m * COLS + n));
printf("a[%d][%d] = %d\n", m, n, a[m][n]);
return 0;
}5.指针
5.1.取地址运算
5.1.1.运算符&:
scanf("%d", &i);里的;获得变量的地址,它的操作数必须是变量。
变量地址的大小
sizeof(&i)是否与int相同取决于编译器。%p用于打印地址。
#include <stdio.h>
int main() {
int i = 0;
int* p = &i;
printf("sizeof(int) = %d\n", sizeof(int)); // 4(字节)
printf("sizeof(&i) = %d\n", sizeof(&i)); // 8(字节)
printf("0x%x\n", &i); // 0x62fe14
printf("%p\n", &i); // 000000000062FE14
printf("%p", p); // 000000000062FE14
return 0;
}&不能対没有地址的东西取地址:
&(a+b)&(a++);&(++a)
5.1.2.数组的地址
#include <stdio.h>
int main() {
int a[10];
printf("%p\n", &a); // 000000000062FDF0
printf("%p\n", a); // 000000000062FDF0
printf("%p\n", &a[0]); // 000000000062FDF0
printf("%p\n", &a[1]); // 000000000062FDF4
return 0;
} 5.2.指针
指针变量就是保存地址的变量。
int i;
int* p = &i; // p是一个指针变量,指向的是int类型的数据
int* p,q; // p是一个指针,q是一个int变量
int *p,q; // p是一个指针,q是一个int变量作为参数的指针
在函数f()里面可以通过这个指针访问main()里的int i。
#include <stdio.h>
void f(int *p);
int main() {
int i = 0;
f(&i);
return 0;
}
void f(int *p) {
printf("p = %p\n", p); // p = 000000000062FE1C
}
访问地址上的变量
*是一个单目运算符,用来访问指针的值所表示的地址上的变量。可以做右值也可以做左值。
int k = *p。*p = k + 1。
#include <stdio.h>
void f(int *p);
void g(int k);
int main() {
int i = 6;
f(&i);
g(i);
return 0;
}
void f(int *p) {
printf("p = %p\n", p); // p = 000000000062FE1C
printf("*p = %d\n", *p); // *p = 6
*p = 26;
}
void g(int k) {
printf("k = %d\n", k); // 26
}*左值之所以叫做左值是因为:
出现在赋值号左边的不是变量,而是值,是表达式计算的结果:
a[0] = 2。*p = 3。
是特殊的值,所以叫做左值。
5.3.指针与数组
数组参数
以下四种函数原型是等价的:
int sum(int *ar, int);
int sum(int *, int);
int sum(int ar[], int);
int sum(int [], int);数组变量是特殊的指针,因此:
int a[10];
// 1、不需要用&取地址
int *p = a;
a == &a[0]; // 数组a的地址等于a[0]的地址
// 2、但是数组的单元表达的是变量,需要用&取地址
int *f = &a[1];数组变量是const指针不能被赋值
#include <stdio.h>
int main() {
int a[5] = {1,2,3,4,5};
int *q = a;
printf("q[0] = %d\n", q[0]); // 1
printf("q[1] = %d\n", q[1]); // 2
printf("q[2] = %d\n", q[2]); // 3
printf("q[3] = %d\n", q[3]); // 4
printf("q[4] = %d\n", q[4]); // 5
return 0;
}5.4.指针与const
// 判断哪个被const了的标志是const在*的前面还是后面
int i;
// 指针所指的东西不可被修改
const int *p1 = &i;
int const *p2 = &i;
// 指针不可修改
int *const p3 = &i;5.5.指针运算
指针加减
#include <stdio.h>
int main() {
// sizeof(char) = 1
char ac[] = {0,1,2,3,4,5,6,7,8,9};
char *p = ac;
printf("p = %p\n", p); // 000000000062FE00
printf("p+1 = %p\n", p+1); // 000000000062FE01
printf("***********************************\n");
// sizeof(int) = 4
int ai[] = {0,1,2,3,4,5,6,7,8,9};
int *q = ai;
printf("q = %p\n", q); // 000000000062FDD0
printf("q+1 = %p\n", q+1); // 000000000062FDD4
return 0;
}*p++是什么意思:
取出p所指的那个数据来,完事之后顺便把p移到下一个位置去。
*优先级虽然高,但是没有++高。
常用语数组类的连续空间操作。
#include <stdio.h>
int main() {
int ai[] = {1,2,3,4,5,6};
int len = sizeof(ai)/sizeof(ai[0]);
int *p = ai;
for(int i = 1; i <= len; i++) {
printf("%d\n", *p++);
}
}指针比较
<、<=、==、>、>=、!=都可以対指针做。比较它们在内存中的地址。
数组中的单元的地址肯定是线性递增的。
5.6.动态内存分配
#include <stdio.h>
#include <stdlib.h>
int main() {
int number = 10;
int* a;
// 动态内存分配
a = (int*)malloc(number * sizeof(int));
for(int i = 0; i < number; i++) {
a[i] = i + 10;
}
for(int i = number - 1; i >= 0; i--) {
printf("%d ", a[i]);
}
// 释放内存
free(a);
return 0;
}free()释放内存:
申请过的空间,最终都是要还的。
只能还申请来的空间的首地址。
6.字符串
6.1.字符串的表示
什么是字符串:
以0(整数0)结尾的一串字符;
0或'\0'是一样的,但是和'0'不同。
0标志字符串的结束,但它不是字符串的一部分。计算字符串长度的时候不包含这个
0。
字符串以数组的形式存在,以数组或指针的形式访问。
更多的是以指针的形式。
string.h里有很多处理字符串的函数。
#include <stdio.h>
int main() {
// 字符数组
char word1[] = {'H','e','l','l','o','!'};
// 还是字符字符数组 ==> 同时成为C语言的字符串
char word2[] = {'H','e','l','l','o','!','\0'};
return 0;
} 字符串变量的表示形式
// 1、指针str指向了字符数组"Hello"
char *str = "Hello";
// 2、这里有一个字符数组,内容是"Hello"
char word[] = "Hello";
// 3、”Hello“这5个字符在line[]数组中占6个位置
char line[10] = "Hello";字符串常量
"Hello"是字符串常量:
Hello会被编译器变成一个字符数组放在某处,这个数组的长度是6,结尾还有表示结束的0。两个相邻的字符串常量会被自动连接起来。
#include <stdio.h>
int main() {
// 自动拼接了!
// aaaabbbb
printf("aaaa"
"bbbb");
} 小总结
C语言的字符串是以字符数组的形态存在的。
不能用运算符対字符串做运算。
通过数组的方式可以遍历字符串。
唯一特殊的地方是字符串字面量可以用来初始化字符数组。
6.2.字符串变量
字符串常量"Hello World"
#include <stdio.h>
int main() {
const char *s1 = "Hello World";
const char *s2 = "Hello World";
printf("s1 = %p\n", s1); // 0000000000404000
printf("s1 = %p\n", s2); // 0000000000404000
} s1 s2两个指针,指向同一个字符串常量。这个常量所在的地方是只读的,不能被修改!
如果需要修改字符串,需要用数组来定义:
char s[] = "Hello World";。

定义字符串使用指针还是数组?
// 指针:这个字符串不知道在哪里(只读)
// 用于处理参数 和 动态分配空间
const char *str = "Hello";
// 数组:这个字符串在这里(可以修改)
// 作为本地变量,空间会被自动回收
char word[] = "Hello";一句话:构造一个字符串用数组,处理一个字符串用指针。
char*是字符串?
字符串可以表达为
char*的形式。char*不一定是字符串。本意是指向字符的指针,可能是指向的是字符的数组(就像
int *一样)。只有
char*所指的字符数组有结尾的0,才能说它所指的是字符串。
6.3.字符串输入输出
字符串安全的输入
char string[8];
// scanf读入一个单词(到空格、tab或者回车为止)
// scanf是不安全的,因为不知道要读入的内容的长度
scanf("%s", string);
// 这个scanf是安全的
// 7代表最多只能读7个字符,因为要有结束的0
scanf("%7s", string);
printf("%s\n", string);#include <stdio.h>
/**
* 1、%5s:是把变量的值保持长度5位(不足5位时),不足5位在前面用空格补齐,
* 超过5位就不用补空格,直接显示部,以字符串方 式输出。
*
* 2、%-5s:是把变量的值保持长度5位(不足5位时),不足5位在后面用空格补齐,
* 超过5位就不用补空格,直接显示全部,以字符串方式输出。
*/
int main(int argc, char const *argv[]) {
const char *s1 = "123456";
const char *s2 = "1234";
printf("-------------正常-------------\n");
printf("%s\n", s1); // 123456
printf("%s\n", s2); // 1234
printf("-------------%5s-------------\n");
printf("%5s\n", s1); // 123456
printf("%5s\n", s2); // 1234(左侧补空格,右对齐)
printf("-------------%-5s-------------\n");
printf("%-5s\n", s1); // 123456
printf("%-5s\n", s2); // 1234
return 0;
}常见错误
// 错误的!!
char *string;
scanf("%s", string);以为
char*就是字符串类型,定义了一个字符串类型的变量string就可以直接使用了。由于没有对
string初始化为0,所以不一定每次运行都出错。
6.4.字符串数组
#include <stdio.h>
/**
* 字符串数组:两种完全不一样的形式
*/
int main(int argc, char const *argv[]) {
const char* arr1[] = {"aaa","bbb","ccc"};
char arr2[][4] = {"aaa","bbb","ccc"};
printf("%s\n", arr1[0]); // aaa
printf("%s\n", arr2[0]); // bbb
return 0;
}
#include <stdio.h>
int main() {
// char* a[] 表示字符串数组
const char* a[] = {"Hello", "World"};
printf("%s\n", a[0]);
printf("%s\n", a[1]);
}
main()函数其实是有参数的
#include <stdio.h>
/*
* 输出:
* argc = 1
* ***********************************
* argv[0] = E:\DevC++\CLanguage\053-字符串.exe
*/
int main(int argc, char const *argv[]) {
printf("argc = %d\n", argc);
printf("***********************************\n");
for(int i = 0; i < sizeof(argv)/sizeof(argv[0]); i++) {
printf("argv[%d] = %s\n", i, argv[i]);
}
return 0;
}6.5.单字符输入输出
#include <stdio.h>
/**
* windows 输入 ctrl + Z 就会输出EOF
*
* 1、getchar(): getchar()函数的作用是从计算机终端(一般为键盘)获取一个无符号字符。getchar()函数只能接收一个字 * 符,其函数值就是从输入设备获取到的字符。
*
* 2、putchar():putchar语法结构为 int putchar(int char) ,其功能是把参数 char 指定的字符(一个无符号字符)写入* 到标准输出 stdout 中,为C 库函数 ,包含在C 标准库 <stdio.h>中。其输出可以是一个字符,可以是介于0~127之间 的 * 一个十进制整型数(包含0和127),也可以是用char定义好的一个字符型变量。
*/
int main() {
int ch;
while((ch = getchar()) != EOF) {
putchar(ch);
}
printf("EOF\n");
return 0;
}6.6.字符串函数
#include <string.h>
strlen。strcmp。strcpy。strcat。strchr。strstr。
案例
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
/**
* 编写一个函数char *stuff(char *str1, char *str2, int i, int j)
* 将串str1中的第i个字符到第j个字符之间的字符串替换成str2。
*/
char *stuff(char *str1, char *str2, int i, int j) {
int len1 = strlen(str1);
int len2 = strlen(str2);
int len = len1 - (j - i + 1) + len2;
char *str3 = (char*)malloc(sizeof(char)*(len + 1));
str1[i-1] = '\0';
strcpy(str3, str1);
strcpy(str3 + i - 1, str2);
strcpy(str3 + i - 1 + len2, str1 + j);
return str3;
}
int main(int argc, char const *argv[]) {
char str1[20] = "yangmingyu";
char str2[10] = "LLX";
char *str3 = stuff(str1, str2, 5, 8);
puts(str3);
return 0;
}6.6.1.strlen
strlen()的作用:
/**
* @Param const char *s 指向字符串的指针
* @Return 字符串的长度
*/
size_t strlen(const char *s); // 返回字符串长度(不包括结尾的0)strlen()的基本使用:
#include <stdio.h>
#include <string.h>
/**
* 自己写的计算字符串长度的函数
*
* *s++:取出当前的值,并使指针向右移一位
*
* @Param const char *s 指向字符串的指针s
* @Return 字符串的长度(不包括结尾的'\0')
*/
int mylenUsedPonit(const char *s) {
int len = 0;
while(*s++ != '\0') len++;
return len;
}
/**
* 数组实现
*
* @Param const char *s 指向字符串的指针
* @Return 字符串的长度(不包括结尾的'\0')
*/
int mylen(const char *s) {
int idx = 0;
while(s[idx]) idx++;
return idx;
}
int main(int argc, char const *argv[]) {
char line[] = "Hello";
printf("*************C语言函数库实现*************\n");
printf("strlen = %lu\n", strlen(line)); // 5(长度)
printf("sizeof = %lu\n", sizeof(line)); // 6(字节)
printf("\n*************数组实现*************\n");
printf("strlen = %lu\n", mylen(line));
printf("\n*************指针实现*************\n");
printf("strlen = %lu\n", mylenUsedPonit(line)); // 5(长度)
return 0;
}6.6.2.strcmp
strcmp()的作用:
/**
* @Return 0: s1==s2
* 1: s1>s2
* -1: s1<s2
*/
int strcmp(const char *s1, const char *s2); // 比较两个字符串返回整数
// 当strcmp在if语句中做判断条件时,需要strcmp(s1, s2) == 0才可以。
// 因为结果等于0正好是if语句不能执行的条件
if(strcmp(s1, s2) == 0) {
}strcmp()的基本使用:
#include <stdio.h>
#include <string.h>
/**
* 指针实现
*/
int mycmpUsedPoint(const char *s1, const char *s2) {
/**
* 1、自己写的!
* while(*s1++ == *s2++ && *(s1-1) != '\0');
* return *(s1-1) - *(s2-1);
*/
// ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ 分隔符~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~
// 2、老师写的!
while(*s1 == *s2 && *s1 != '\0') {
s1++;
s2++;
}
return *s1 - *s2;
}
/**
* 数组实现
*/
int mycmp(const char *s1, const char *s2) {
int idx = 0;
while(s1[idx] == s2[idx] && s1[idx] != '\0') {
idx++;
}
return s1[idx] - s2[idx];
}
int main(int argc, char const *argv[]) {
char s1[] = "abc";
char s2[] = "abc";
const char *s3 = "bbc";
const char *s4 = "Abc";
printf("********************************C语言库的函数********************************\n");
/**
* 数组的比较永远都是false,
* 因为两个数组的地址是不同的
*/
printf("s1 == s2? ==> %d\n", s1 == s2); // 0(不相等)
printf("strcmp(s1,s2) = %d\n", strcmp(s1, s2)); // 0(s1 == s2)
printf("strcmp(s1,s3) = %d\n", strcmp(s1, s3)); // -1(s1 < s3)
printf("strcmp(s1,s4) = %d\n", strcmp(s1, s4)); // 1(s1 > s4)
printf("'a' - 'A' = %d\n", 'a' - 'A'); // 32('a'和'A'距离是32)
printf("********************************数组实现********************************\n");
printf("mycmp(s1,s2) = %d\n", mycmp(s1, s2));
printf("mycmp(s1,s3) = %d\n", mycmp(s1, s3));
printf("mycmp(s1,s4) = %d\n", mycmp(s1, s4));
printf("********************************指针实现********************************\n");
printf("mycmpUsedPoint(s1,s2) = %d\n", mycmpUsedPoint(s1, s2));
printf("mycmpUsedPoint(s1,s3) = %d\n", mycmpUsedPoint(s1, s3));
printf("mycmpUsedPoint(s1,s4) = %d\n", mycmpUsedPoint(s1, s4));
return 0;
}程序运行结果:
********************************C语言库的函数********************************
s1 == s2? ==> 0
strcmp(s1,s2) = 0
strcmp(s1,s3) = -1
strcmp(s1,s4) = 1
'a' - 'A' = 32
********************************数组实现********************************
mycmp(s1,s2) = 0
mycmp(s1,s3) = -1
mycmp(s1,s4) = 32
********************************指针实现********************************
mycmpUsedPoint(s1,s2) = 0
mycmpUsedPoint(s1,s3) = -1
mycmpUsedPoint(s1,s4) = 32
--------------------------------
Process exited after 0.06953 seconds with return value 0
请按任意键继续. . .6.6.3.strcpy
strcpy()的作用:
/**
* restrict关键字表明src和dst不重叠(c99)
* @Param char * restrict det 目标字符串
* @Param char * restrict src 源字符串
* @Return 目标字符串
*/
char * strcpy(char * restrict dst, const char * restrict src); // 把src的字符串拷贝到dstrestrict不能重叠?什么是重叠?OK!请看下图!

strcpy()的基本使用:
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
/**
* 指针实现
*
* @Param char *dst 指向目标字符串的指针
* @Param const char *src 指向源字符串的指针
* @Return char *dst 指向目标字符串的指针
*/
char * mycopyUsedPoint(char *dst, const char *src) {
char *temp = dst;
// while(*src) 等价于 while(*src != '\0')
while(*src) *temp++ = *src++;
*temp = '\0';
return dst;
}
/**
* 数组实现
*
* @Param char *dst 指向目标字符串的指针
* @Param const char *src 指向源字符串的指针
* @Return char *dst 指向目标字符串的指针
*/
char * mycopy(char *dst, const char *src) {
int idx = 0;
// while(src[idx] != '\0') 等价于 while(src[idx])
while(src[idx]) {
dst[idx] = src[idx];
idx++;
}
dst[idx] = '\0';
return dst;
}
int main(int argc, char const *argv[]) {
const char *src = "Hello World!";
printf("***************C语言函数库***************\n");
/**
* 为dst动态分配内存
* 注意:strlen(src)是不包括结果的'\0'的 一定要记住+1!!!
*/
printf("sizeof(src) = %d\n", sizeof(src)); // 8(表示的是char*指针的大小)
printf("sizeof(char*) = %d\n", sizeof(char*)); // 8
printf("strlen(src) = %d\n", strlen(src)); // 12
char *dst = (char*)malloc(strlen(src) + 1);
printf("dst = %s\n", strcpy(dst, src));
printf("\n***************数组实现***************\n");
char *dst1 = (char*)malloc(strlen(src) + 1);
printf("dst1 = %s\n", mycopy(dst1, src));
printf("\n***************指针实现***************\n");
char *dst2 = (char*)malloc(strlen(src) + 1);
printf("dst2 = %s\n", mycopyUsedPoint(dst2, src));
return 0;
}6.6.4.strcat
strcat()的作用:
/**
* src + dst 合并到一起
* dst必须要有足够的空间
*
* @Param char *restrict dst 指向目标字符串的指针
* @Param const char *restrict src 指向源字符串的指针
* @Return char *restrict dst 指向目标字符串的指针
*/
char * strcat(char *restrict dst, const char *restrict src); // 将src拷贝到dst的后面,结成一个长的字符串字符串如何拼接的???请看下图!

strcat()的基本使用:
#include <stdio.h>
#include <string.h>
/**
* 指针实现
*
* @Param char *dst 指向目标字符串的指针
* @Param const char *src 指向源字符串的指针
* @Return char *dst 指向目标字符串的指针
*/
char * mycatUsedPoint(char *dst, const char *src) {
int lenOfdst = strlen(dst);
char *temp = dst;
dst += lenOfdst; // dst初始化指向'\0'
while(*src) *dst++ = *src++; // while(*src) 等价于 while(*src != '\0')
*dst = '\0';
return temp;
}
/**
* 数组实现
*
* @Param char *dst 指向目标字符串的指针
* @Param const char *src 指向源字符串的指针
* @Return char *dst 指向目标字符串的指针
*/
char * mycat(char *dst, const char *src) {
int lenOfdst = strlen(dst);
int idx_dst = lenOfdst; // dst索引初始化在'\0'的位置
int idx_src = 0;
while(src[idx_src]) { // while(src[idx_src]) 等价于 while(src[idx_src] != '\0')
dst[idx_dst] = src[idx_src];
idx_src++;
idx_dst++;
}
dst[idx_dst] = '\0';
return dst;
}
int main(int argc, char const *argv[]) {
char dst[100] = "Hello";
const char *src = " World!";
printf("*************C语言函数库实现*************\n");
printf("dst = %s\n", strcat(dst, src));
printf("\n*************数组实现*************\n");
char dst1[100] = "你好,";
const char *src1 = "中国!";
printf("dst1 = %s\n", mycat(dst1, src1));
printf("\n*************指针实现*************\n");
char dst2[100] = "Great ";
const char *src2 = "progress!";
printf("dst2 = %s\n", mycatUsedPoint(dst2, src2));
return 0;
}6.6.5.安全版本
char * strncpy(char *restrict dst, const char *restrict src, size_t n); // 最多拷贝n个字符
char * strncat(char *restrict s1, const char *restrict s2, size_t n); // 最多连接n个字符
char * strncmp(const char *s1, const char *s2, size_t n); // 比较前n个字符6.6.6.字符串搜索函数
strchr()、strrchr()的作用:
/**
* 从字符串左边找字符
* @Param const char *s 指向字符串的指针
* @Param int c 要查找的字符
* @Return 指针(NULL表示没有找到)
*/
char *strchr(const char *s, int c);
/**
* 从字符串右边找字符
* @Param const char *s 指向字符串的指针
* @Param int c 要查找的字符
* @Return 指针(NULL表示没有找到)
*/
char *strrchr(const char *s, int c);strchr()的基本使用:
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
/**
* strchr()函数
*
* 技巧1:如何寻找第二个'l'?
*/
void selectSecondChar() {
char s[] = "Hello";
char *p = strchr(s, 'l');
printf("%s\n", p); // llo
p = strchr(p+1, 'l');
printf("%s\n", p); // lo
}
/**
* strchr()函数
*
* 技巧2:如何找到'l'并将'l'后面的字符拷贝到其他字符串?
*/
void selectAndCopy() {
char s[] = "Hello";
char *p = strchr(s, 'l');
char *t = (char*)malloc(strlen(p) + 1);
printf("t = %s\n", strcpy(t, p)); // llo
free(t);
}
/**
* strchr()函数
*
* 技巧3:如何截取"He"?
*/
void getBeforeString() {
char s[] = "Hello";
char *p = strchr(s, 'l');
char c = *p;
*p = '\0';
char *t = (char*)malloc(strlen(s) + 1);
printf("t = %s\n", strcpy(t, s)); // He
*p = c;
printf("s = %s\n", s); // Hello
free(t);
}
int main() {
selectSecondChar();
selectAndCopy();
getBeforeString();
return 0;
}7.结构
7.1.枚举
7.1.1.枚举的使用
枚举是什么?
/**
* 枚举是一种用户定义的数据类型,用关键字enum来定义
*/
enum 枚举类型名字 {名字0,...,名字n};
/**
* 枚举类型名字通常并不真的使用,要用的是在大括号里的名字,因为它们就是常量符合,
* 它们的类型是int,值依次从0到n。
*/
enum colors {red, yellow, green};枚举的简单使用
枚举量可以作为值。
枚举类型可以跟上
enum作为类型。枚举实际上是以整数来做内部计算和外部输入输出的。
#include <stdio.h>
/**
* 定义枚举类型:我们自己自己定义的一种数据类型
*/
enum colors {
red,
yellow,
green
};
// 可以使用枚举类型传参(一定要加上enum)
void f(enum colors c);
int main(int argc, char const *argv[]) {
// 可以使用我们定义枚举类型(一定要加上enum)
enum colors c1 = red;
enum colors c2 = yellow;
enum colors c3 = green;
f(c1); // 0
f(c2); // 1
f(c3); // 2
printf("\n----------------------------\n");
f(red); // 0
f(yellow); // 1
f(green); // 2
return 0;
}
void f(enum colors c) {
printf("%d\n", c);
}7.1.2.枚举自动计数
套路:自动计数的枚举
#include <stdio.h>
/**
* RED:0
* YELLOW:1
* GREEN:2
* NumCOLORS:3 //就代表以上颜色的个数,自动计数的功能
*/
enum COLOR {
RED,
YELLOW,
GREEN,
NumCOLORS
};
int main(int argc, char const *argv[]) {
int color = -1;
// 定义字符串数组
const char *colorNames[NumCOLORS] = {"red", "yellow", "green"};
// 定义指向字符串的指针
const char *colorName = NULL;
printf("请输入你喜欢的颜色代码:\n");
scanf("%d", &color);
if(color >= 0 && color < NumCOLORS) {
colorName = colorNames[color];
} else {
colorName = "unknown";
}
printf("你喜欢的颜色是%s\n", colorName);
return 0;
}7.1.3.枚举小总结
声明枚举量的时候可以指定值。
枚举只是
int。即使给枚举类型的变量赋不存在的整数值也没有任何warning error。虽然枚举类型可以当做数据类型使用,但是实际上很少用。
如果有意义上排比的名字,用枚举比
const int好。枚举比宏
macro好,因为枚举有int类型。
#include <stdio.h>
enum color {
red = 1,
yellow,
green = 5,
blue,
};
int main(int argc, char const *argv[]) {
printf("red for enum color is %d\n", red); // 1
printf("yellow for enum color is %d\n", yellow); // 2
printf("green for enum color is %d\n", green); // 5
printf("blue for enum color is %d\n", blue); // 6
return 0;
}7.2.结构类型
7.2.1.声明结构类型
声明结构
结构类型和本地变量一样,在函数内部声明结构类型只能在当前函数内使用。
所有通常在函数外部声明结构类型,这样就可以被多个函数使用了。
#include <stdio.h>
/**
* Case1:声明结构
*/
struct point {
int x;
int y;
};
/**
* Case2:声明结构
*
* p2,p3是一种无名结构,里面有x和y,
* 被编译器警告了,不推荐有无名结构。
*/
struct {
int x;
int y;
} p2, p3;
/**
* Case3:声明结构
*
* 这种声明结构的方式做了两件事:
* - 1.声明了一个结构叫做point1;
* - 2.定义了两个point1类型的变量 p4,p5。
*/
struct point1 {
int x;
int y;
} p4, p5;
int main(int argc, char const *argv[]) {
printf("***************Case1的使用***************\n");
struct point p1;
p1.x = 3;
p1.y = 5;
printf("(%d,%d)\n", p1.x, p1.y); // (3,5)
printf("***************Case2的使用***************\n");
p2.x = 8;
p2.y = 8;
printf("(%d,%d)\n", p2.x, p2.y); // (8,8)
printf("***************Case3的使用***************\n");
p4.x = 63;
p4.y = 79;
printf("(%d,%d)\n", p4.x, p4.y); // (63,79)
return 0;
}结构的初始化
#include <stdio.h>
struct date {
int month;
int day;
int year;
};
int main(int argc, char const *argv[]) {
struct date today = {8, 26, 2020};
struct date thisMonth = {.month = 8, .day = 0, .year = 2020};
// %i 在printf里 和 %d没有区别
// %i 在scanf里会识别b八进制、16进制输入,并转换成10进制
printf("Today's date is %i-%i-%i.\n",
today.year, today.month, today.day);
printf("This month is %i-%i-%i.\n",
thisMonth.year, thisMonth.month, thisMonth.day);
return 0;
}结构成员
结构和数组有点像:
数组用
[]运算符和下标访问其成员。a[0] = 10。
结构用
.运算符和名字访问其成员。today.day;p1.x;p1.y;
结构运算
要访问整个结构,直接用结构变量的名字。
对于整个结构,可以做赋值、取地址,也可以传递给函数参数。
#include <stdio.h>
struct point {
int x;
int y;
}p1, p2;
int main(int argc, char const *argv[]) {
p1.x = 5;
p1.y = 3;
printf("p1 = (%d, %d)\n", p1.x, p1.y); // p1 = (5, 3)
p2 = p1; // 相当于p2.x = p1.x; p2.y = p1.y
printf("p2 = (%d, %d)\n", p2.x, p2.y); // p2 = (5, 3)
return 0;
}结构指针
和数组不同,结构变量的名字并不结构变量的地址,必须使用
&运算符。struct date *pDate = &today;
#include <stdio.h>
struct date {
int month;
int day;
int year;
};
int main(int argc, char const *argv[]) {
struct date today = {8, 26, 2020};
struct date thisMonth = {.month = 8, .day = 0, .year = 2020};
/**
* %i 在printf里 和 %d没有区别
* %i 在scanf里会识别b八进制、16进制输入,并转换成10进制
*/
printf("Today's date is %i-%i-%i.\n",
today.year, today.month, today.day); // 输出:Today's date is 2020-8-26.
printf("This month is %i-%i-%i.\n",
thisMonth.year, thisMonth.month, thisMonth.day); // 输出:This month is 2020-8-0.
printf("--------------------------分隔符--------------------------\n");
struct date *pDate = &today; // 定义结构指针并取today的地址
printf("pDate = %p\n", pDate); // pDate = 000000000062FE00
pDate->year = 2021; // 修改today中的值
printf("Today's date is %i-%i-%i.\n",
today.year, today.month, today.day); // 输出:Today's date is 2021-8-26.
return 0;
}7.2.2.结构与函数
结构作为函数参数
int numberOfDays(struct date d);整个结构可以作为参数的值传入函数。
这时候是在函数内新建一个结构变量,并复制调用者的结构的值。
也可以返回一个结构。
#include <stdio.h>
struct date {
int month;
int day;
int year;
};
/**
* 判断当前year是否是闰年
*
* @Param struct date d 结构date(年月日)
* @Reutrn true:闰年;false:平年
*/
bool isLeap(struct date d);
/**
* 计算当前月最多有多少天
*
* @Param struct date d 结构date(年月日)
* @Return 当前月的天数
*/
int numberOfDays(struct date d);
int main(int argc, char const *argv[]) {
struct date today, tomorrow; // 定义struct date类型的变量 today, tomorrow
printf("输入今天的日期(yyyy mm dd)\n");
/**
* &today.year: 这里是取(today.year)的地址!
* 一定是先获得today的成员,然后再取成员的地址
*/
scanf("%i %i %i", &today.year, &today.month, &today.day);
if(today.day != numberOfDays(today)) { // 如果today不是本月的最后一天
tomorrow.day = today.day + 1;
tomorrow.month = today.month;
tomorrow.year = today.year;
} else if(today.month == 12) { // 如果today是12月的最后一天
tomorrow.day = 1;
tomorrow.month = 1;
tomorrow.year = today.year + 1;
} else { // 如果today是其他月份(除了12月)的最后一天
tomorrow.day = 1;
tomorrow.month = today.month + 1;
tomorrow.year = today.year;
}
printf("明天的日期是:%i-%i-%i.\n", tomorrow.year, tomorrow.month, tomorrow.day);
return 0;
}
int numberOfDays(struct date d) {
int days;
const int daysPerMonth[12] = {31, 28, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31};
if(d.month == 2 && isLeap(d)) {
days = 29;
} else {
days = daysPerMonth[d.month - 1];
}
return days;
}
bool isLeap(struct date d) {
bool leap = false;
if((d.year % 4 == 0 && d.year % 100 != 0) || d.year % 400 == 0) {
leap = true;
}
return leap;
}输入结构
没有直接的方式可以一次
scanf()一个结构。但是读入的结构如何送回来呢?
记住C语言在函数调用时是传值的!
如果我们打算写一个函数来输入结构呢?
#include <stdio.h>
struct point {
int x;
int y;
};
/**
* 直接对mian()中的变量做修改
*
* @Param struct point *p 变量的地址
*/
void getStruct(struct point *p);
/**
* 将mian()的变量拷贝一份并输出
*
* @Param struct point p 变量
*/
void putStruct(struct point p) ;
int main(int argc, char const *argv[]) {
struct point p = {0, 0}; // 声明struct point类型变量p并初始化
getStruct(&p); // 対变量p做修改
printf("main() --> (%d, %d)\n", p.x, p.y); // 在mian()打印变量p
putStruct(p); // 写一个函数打印变量p
return 0;
}
void getStruct(struct point *p) {
scanf("%d", &p->x); // scanf()中要取到成员变量x的地址(&p->x)
scanf("%d", &p->y);
printf("getStruct --> (%d, %d)\n", p->x, p->y);
}
void putStruct(struct point p) {
printf("putStruct --> (%d, %d)\n", p.x, p.y);
}指向结构的指针
struct date {
int month;
int day;
int year;
}myday;
struct date *p = &myday;
p->month = 12; // (*p).month = 12対之前从程序做一点点修改:
#include <stdio.h>
struct point {
int x;
int y;
};
/**
* 直接对mian()中的变量做修改
*
* @Param struct point *p 变量的地址
* @Return 变量的地址
*/
struct point * getStruct(struct point *p);
/**
* 将mian()的变量拷贝一份并输出
*
* @Param struct point p 变量
*/
void putStruct(struct point p) ;
int main(int argc, char const *argv[]) {
struct point p = {0, 0}; // 声明struct point类型变量p并初始化
putStruct(*getStruct(&p)); // 対变量p做修改 并 打印变量p
printf("main() --> (%d, %d)\n", p.x, p.y); // 在mian()打印变量p
return 0;
}
struct point * getStruct(struct point *p) {
scanf("%d", &p->x); // scanf()中要取到成员变量x的地址(&p->x)
scanf("%d", &p->y);
printf("getStruct --> (%d, %d)\n", p->x, p->y);
return p;
}
void putStruct(struct point p) {
printf("putStruct --> (%d, %d)\n", p.x, p.y);
}7.2.3.结构数组
#include <stdio.h>
struct time {
int hour;
int minutes;
int seconds;
};
/**
* 计算下一秒的时间
*
* @Param struct time now 当前的时间
* @Return 下一秒的时间
*/
struct time timeUpdate(struct time now);
int main(int argc, char const *argv[]) {
// 定义结构数组 并 初始化
struct time testTimes[] = {
{11, 59, 59}, {12, 0, 0}, {1, 29, 59}, {23, 59, 59}, {19, 12, 27},
};
int len = sizeof(testTimes) / sizeof(testTimes[0]);
printf("len = %d\n", len);
for(int i = 0; i < len; i++) {
printf("当前时间是: %.2i:%.2i:%.2i\n",
testTimes[i].hour, testTimes[i].minutes, testTimes[i].seconds);
testTimes[i] = timeUpdate(testTimes[i]);
printf("一秒之后时间是: %.2i:%.2i:%.2i\n",
testTimes[i].hour, testTimes[i].minutes, testTimes[i].seconds);
}
return 0;
}
struct time timeUpdate(struct time now) {
now.seconds++;
if(now.seconds == 60) {
now.seconds = 0;
now.minutes++;
if(now.minutes == 60) {
now.minutes = 0;
now.hour++;
if(now.hour == 24) {
now.hour = 0;
}
}
}
return now;
}7.2.4.嵌套的结构
struct piont {
int x;
int y;
};
struct rectangle {
struct piont pt1;
struct piont pt2;
};
// 定义变量
struct rectangle r, *rp;
rp = &r;
// 以下四种形式是等价的
r.pt1.x;
rp->pt1.x;
(r.pt1).x;
(rp->pt1).x;
7.3.typedef
typedef的作用:
// C语言提供了一个叫做typedef的功能来声明一个已有的数据类型的新名字
// 使得Length成为int类型的别名
// 这样,Length这个名字就可以代替int出现在变量定义和参数声明的地方了
typedef int Length;
Length a, b, len;
Length numbers[10];
// ------------------------------------分隔符--------------------------------------------
/**
* struct ADate 是原有的数据类型
* Date是为struct ADate数据类型起的别名
*/
typedef struct ADate {
int month;
int day;
int year;
} Date;7.4.union
#include <stdio.h>
/**
* 成员变量i和ch使用相同的内存空间!
* 通过i在内存中存入值后, ch也有值了。
* 通过ch在内存中存入值后, i也有值了。
*/
typedef union {
int i;
char ch[sizeof(int)];
} CHI;
int main(int argc, char const *argv[]) {
CHI chi;
chi.i = 1234; // 16进制是 00 00 04 D2
for(int i = 0; i < sizeof(int); i++) {
printf("%02hhX", chi.ch[i]); // D2040000
}
printf("\n");
return 0;
}
8.全局变量
8.1.全局变量
定义全局变量
定义在函数外面的变量是全局变量。
全局变量具有全局的生存期和作用域。
全局变量与任何函数都无关。
在任何函数内部都可以使用全局变量。
#include <stdio.h>
int f();
// 定义全局变量
int gAll = 12;
int main(int argc, char const *argv[]) {
// __func__:打印当前函数的名字
printf("in %s gAll = %d\n", __func__, gAll); // in main gAll = 12
f();
printf("in %s gAll = %d\n", __func__, gAll); // in main gAll = 14
return 0;
}
int f() {
printf("in %s gAll = %d\n", __func__, gAll); // in f gAll = 12
gAll += 2;
printf("in %s gAll = %d\n", __func__, gAll); // in f gAll = 14
return gAll;
}全局变量的初始化
没有做初始化的全局变量会得到0值。
指针会得到
NULL值。
只能用编译时刻已知的值来初始化全局变量。
他们的初始化发生在
main()之前。如果函数内部存在与全局变量同名的变量,则全局变量会被隐藏。
#include <stdio.h>
int f();
// 定义全局变量
int gAll = 12;
// 不要这样初始化全局变量
int g2 = gAll;8.2.静态本地变量
在本地变量定义时加上
static修饰符就成为静态本地变量。当函数离开的时候,静态本地变量会继续存在并保持其值。
静态本地变量的初始化只会在第一次进入这个函数时做,以后进入函数时会保持上次离开时的值。
#include <stdio.h>
/**
* 静态本地变量实际上是特殊的全局变量!
*
* 输出结果:
*
* in f() a = 1
* in f() b = 10
* in f() a = 1
* in f() b = 11
* in f() a = 1
* in f() b = 12
*/
void f() {
int a = 1;
static int b = 10;
printf("in %s() a = %d\n", __func__, a);
printf("in %s() b = %d\n", __func__, b);
a++;
b++;
}
int main(int argc, char const *argv[]) {
f();
f();
f();
return 0;
}8.3.小总结
返回本地变量的地址是危险的。
返回全局变量或静态本地变量的地址是安全的。
返回在函数内
malloc的内存是安全的,但是容易造成问题。最好的做法是返回传入的指针。
不要使用全局变量来在函数间传递参数的结果。
尽量避免使用全局变量。
使用全局变量和静态本地变量的函数是线程不安全的。
9.编译预处理指令和宏
9.1.宏定义
C语言
#开头的是编译预处理指令。他们不是C语言的成分,但是C语言程序离不开它们。
#define用来定义一个宏。
#include <stdio.h>
// const double PI = 3.14159;
/**
* 宏做的是完全的文本替换
*
* 1.注意这里没有分号,这不是C语言的语句。
* 2.如果一个宏中有其他的宏的名字,也会被替换。
* 3.如果一个宏的值超过一行,最后一行之前的行末需要加\。
* 4.宏的值后面出现的注释不会被当作的值的一部分。
*/
#define PI 3.14159 // π
#define FORMAT "%f\n"
#define PI2 2*PI // 2 * π
#define PRT printf("%f\n", PI); \
printf("%f\n", PI2)
int main(int argc, char const *argv[]) {
printf(FORMAT, PI2);
PRT;
return 0;
}C语言定义好的宏:
#include <stdio.h>
/**
* 输出结果:
* E:\DevC++\CLanguage\075-预定义的宏.cpp:4
* Aug 27 2020,20:11:13
*/
int main(int argc, char const *argv[]) {
printf("%s:%d\n", __FILE__, __LINE__);
printf("%s,%s\n", __DATE__, __TIME__);
return 0;
}9.2.带参数的宏
#include <stdio.h>
/**
* 定义的宏的参数是没有类型的!
*
* 带参数的宏的原则:
* 1.一切要有括号
* - 整个值要有括号
* - 参数出现的每个地方都要括号
* 2.#define R1(x) ((x) * 57.29)
* 3.#define R2(x) ((x) * 57.29)
* 4.定义宏千万不要加分号!!!!
*/
#define cube(x) ((x)*(x)*(x))
/**
* 错误定义的宏
* 第一个错误原因:5+2*57.29
* 第二个错误原因:180/1*57.29
*/
#define R1(x) (x * 57.29)
#define R2(x) (x) * 57.29
int main(int argc, char const *argv[]) {
printf("%d\n", cube(5)); // 125
printf("%f\n", R1(5+2)); // 119.580000
printf("%f\n", 180/R2(1)); // 10312.200000
return 0;
} 10.大程序结构
10.1.多个源代码文件
在
DEV C++中新建一个项目,然后把几个源代码文件加入进入。对于项目,
DEV C++的编译会把一个项目中所有的源代码文件都编译后,链接起来。有些
IDE有分开的编译和构建两个按钮,前者是対单个源代码文件编译,后者是対整个项目做链接。
// main.c
#include <stdio.h>
int max(int a, int b);
int main(int argc, char const *argv[]) {
int a = 5;
int b = 6;
printf("%d\n", max(a, b));
return 0;
}
// max.c
int max(int a, int b) {
return a > b ? a : b;
}10.2.头文件
将函数原型放到一个头文件(以.h结尾)中,在需要调用这个函数的源代码文件(.c文件)中#include这个头文件,就能让编译器在编译的时候知道函数原型。
// main.c
/**
* #include <> 还是 ""?
* 1.#include有两种形式来指出要插入的文件;
* 1.1.""要求编译器首先在当前目录(.c文件所在的目录)寻找这个文件,如果没有,
* 到编译器指定的目录去找。
* 1.2.<>让编译只在指定的目录去找。
*
* 2.编译器自己知道自己的标准库的头文件在哪里。
*
* 3.环境变量和编译器命令行参数也可以指定寻找头文件的目录。
*/
#include <stdio.h>
#include "max.h"
int main(int argc, char const *argv[]) {
int a = 5;
int b = 6;
printf("%d\n", max(a, b));
return 0;
}// max.h
int max(int a, int b); // max()函数的原型声明// max.c
#include "max.h"
int max(int a, int b) {
return a > b ? a : b;
}#include
#include是一个编译预处理指令,和宏一样,在编译之前就处理了。它把那个文件的全部文本内容原封不动地插入到它所在的地方。
所以也不是一定要在
.c文件的最前面#include。
#include的误区:
#include不是用来引入库的。stdio.h里只有printf()的原型声明,printf()的代码在另外的地方,某个.lib(windows)。现在的C语言编译器默认会引入所有的标准库。
#include<stdio.h>只是为了让编译器知道printf()的原型,保证调用时给出的参数值是正确的类型。
头文件:
在使用和定义这个函数的地方都应该
#include这个文件。一般的做法就是任何
.c都有对应同名的.h,把所有对外公开的函数的原型和全局变量的声明都放进去。
10.3.声明
int i; // 变量的定义
extern int i; // 变量的声明 声明全局变量
// main.c
#include <stdio.h>
#include "max.h"
int main(int argc, char const *argv[]) {
int a = 5;
int b = 6;
printf("%d\n", max(a, gAll)); // 使用全局变量gAll
return 0;
}// max.c
#include "max.h"
// 定义一个全局变量? 如何在main.c里使用呢?
int gAll = 12;
int max(int a, int b) {
return a > b ? a : b;
}// max.h
int max(int a, int b);
// 声明全局变量gAll,这样就可以在main.c里使用了!
extern int gAll; 声明和定义啥关系?
不产生代码:编译器不会去产生代码,而是默默的记住这个东西。
只有声明可以放在头文件中,是规则不是法律。
声明是不产生代码的东西。
函数原型
变量声明
结构声明
宏声明
枚举声明
类型声明
inline函数
定义是产生代码的东西。
如何防止头文件重复声明???
// 标准头文件结构
#ifndef _LIST_HEAD_
#define _LIST_HEAD_
...
#endif标准头文件结构的使用:
// max.h
#ifndef _MAX_H_
#define _MAX_H_
int max(int a, int b);
// 声明全局变量gAll
extern int gAll;
#endif 11.文件
11.1.格式化输入输出
printf
// printf
%[flags][width][.prec][hlL]type#include <stdio.h>
int main(int argc, const char *argv[]) {
// 总共有9位,保留小数点后2位
printf("%09.2f\n", 123.0); // 000123.00
// * 和 8 对应,这个8可以用变量操作了!
printf("%0*d\n", 8, 123); // 00000123
return 0;
}
scanf
// scanf
%[flag]type

11.2.文件输入输出
#include <stdio.h>
int main(int argc, char const *argv[]) {
/**
* fopen()
* r:打开只读;
* r+:打开读写,从文件头开始;
* w:打开只写,如果不存在则创建,如果存在则清空;
* w+:打开读写,如果不存在则创建,如果存在则清空;
* a:打开追加,如果不存在则创建,如果存在则从文件尾部开始;
* ..x:只新建,如果文件已经存在则不能打开。
*/
FILE *fp = fopen("078_test.txt", "r");
if(fp) {
int num;
fscanf(fp, "%d", &num);
printf("%d\n", num);
fclose(fp);
} else {
printf("无法打开文件\n");
}
return 0;
}FILE、fopen()、fprintf()、fscanf()、fclose()的具体使用。
#include <stdio.h>
#include <cstdlib>
/**
* 编写一个程序,显示指定的文本文件的内容,要求每行中显示的字符数不得超过30个字符。
*/
int main(int argc, char const *argv[]) {
int cnt = 0;
char ch;
FILE *fp = fopen("2.1_test.txt", "w+");
// 1. 判断文件是否存在
if(fp == NULL) {
printf("无法打开文件\n");
exit(0); // exit(0)无条件退出程序
}
// 2. 写文件
puts("please input data:");
for(int i = 1; i <= 10; i++) {
scanf("%c", &ch);
fprintf(fp, "%c", ch); // 写文件
}
rewind(fp); // 重置指针
// 3. 读文件
while(fscanf(fp, "%c", &ch) > 0) {
cnt++;
printf("%c", ch);
if(ch == '\n') {
cnt = 0;
continue;
}
if(cnt % 30 == 0) printf("\n");
}
fclose(fp); // 关闭文件
return 0;
}11.3.二进制文件
其实所有的文件最终都是二进制的。
文本文件无非是用最简单的方式可以读写的文件。
more、tail、cat、vi、vim。Linux方便查看文本文件。而二进制文件是需要专门的程序来读写的文件。
windows喜欢用二进制文件。文件文件的输入输出是格式化过的,可能经过转码。
二进制文件 VS 文本文件
文本优势:方便人类读写,而且跨平台。
文本缺点:程序输入输出需要格式化,开销大。
二进制缺点:人类读写困难,而且不跨平台。
int大小不一致,大小端的问题。。。
二进制优点:程序读写快。
可移植性
二进制文件不具有可移植性。
在
int32位的机器上写成的数据文件无法直接在int为64位的机器上正确读出。
解决方案之一是放弃使用
int,而是用typedef定义具有明确大小的数据类型。更好的方案是使用文本。
12.位运算
12.1.按位运算
#include <stdio.h>
int main(int argc, char const *argv[]) {
char a = 0x5A;
char b = 0x8C;
char c = 0xAA;
//~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ 按位与 ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~
/**
* 1.按位的&运算,只有全1的时候才是1
* 0101 1010
* 1000 1100
* ---------
* 0000 1000
*
* 2.按位与常用于两种应用:
* - 2.1.让某一位或某些位为0:x & 0xFE
* 0xFE:1111 1110
* - 2.2.取一个数中的一段:x & 0XFF
* 0xFF: 1111 1111
*/
printf("0x%hhX\n", a&b); // 0x08
//~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ 按位或 ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~
/**
* 1.按位的|运算,只要有1就是1
* 0101 1010
* 1000 1100
* ---------
* 1101 1110
*
* 2.按位或常用于两种应用:
* - 2.1.使得一位或几个位为1:x | 0x01
* 0x01: 0000 0001
* - 2.2.把两个数拼起来: 0x00FF | 0xFF00
* 0x00FF:0000 0000 1111 1111
* 0xFF00:1111 1111 0000 0000
*/
printf("0x%hhX\n", a|b); // 0xFFDE
//~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ 按位取反 ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~
/**
* 按位取反,1变0,0变1
* 1010 1010
* ---------
* 0101 0101
*/
printf("0x%hhX\n", ~c); // 0x55
//~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ 减法 ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~
/**
* -c
* 10000 0000
* 1010 1010
* ----------
* 0101 0110
*/
printf("0x%hhX\n", -c); // 0x56
/**
* 0101 0110 = 2^6 + 2^4 + 2^2 + 2 = 86
*/
printf("%d\n", -c); // 86
return 0;
}逻辑运算VS按位运算
#include <stdio.h>
int main(int argc, char const *argv[]) {
/**
* 5 & 4 = 4
* 5 && 4 ==> 1 && 1 = 1
*/
printf("5 & 4 = %d\n", 5&4); // 5 & 4 = 4
printf("5 && 4 = %d\n", 5&&4); // 5 && 4 = 1
/**
* 5 | 4 = 5
* 5 || 4 ==> 1 || 1 = 1
*/
printf("5 | 4 = %d\n", 5|4); // 5 | 4 = 5
printf("5 || 4 = %d\n", 5||4); // 5 || 4 = 1
/**
* 4:0000 0100
* ~: 1111 1011(负数以补码形式存在)
*即: 1000 0101(-5的原码)
*
* !4 ==> !1 ==> 0
*/
printf("~4 = %d\n", ~4); // ~4 = -5
printf("!4 = %d\n", !4); // !4 = 0
return 0;
}异或
#include <stdio.h>
int main(int argc, char const *argv[]) {
char a = 0xB4;
char b = 0x4B;
/**
* 异或^:如果两个位相等则为0;不相等则为1.
* 1011 0100
* 0100 1011
* ---------
* 1111 1111
*/
printf("0x%hhX\n", a^b); // 0xFF
// 两次异或B4又回来了!
printf("0x%hhX\n", a^b^b); // 0xB4
return 0;
} 12.2.移位运算
#include <stdio.h>
int main(int argc, char const *argv[]) {
int a = 18;
int b = -10;
/**
* 左移:i << j,i中所有的位向左移动j个位置
* x << 1 <==> x *= 2
* x << n <==> x *= 2^n(2的n次方)
*/
printf("a << 2 = %d\n", a<<2); // a << 2 = 72
/**
* 右移:i >> j,i中所有的位向右移动j个位置
* x >> 1 <==> x /= 2
* x >> n <==> x /= 2^n(2的n次方)
*
* 1000 1010(-10原码)
* 1111 0110(-10的补码,计算机中存储的)
* 1111 1011(-10的补码,向右移1位)
* 1000 0101(再换算成原码是-5)
*/
printf("b >> 1 = %d\n", b>>1); // b >> 1 = -5
return 0;
}12.3.位运算的应用
输出一个数的二进制
#include <stdio.h>
int main(int argc, char const *argv[]) {
int number = 10;
unsigned mask = 1u<<31; // 将1移到最高位(无符号左移)
printf("0x%X\n", mask); // 0x80000000
for( ; mask; mask >>= 1) { // 每做一次&就将1向后移一位
printf("%d", number & mask ? 1 : 0); // &的结果不是全0就返回1,是全0就返回0
}
printf("\n");
return 0;
}13.可变数组
#include <stdio.h>
#include <stdlib.h>
/**
* 定义数组
*
* @Member array: 指向数组(某块地址)的指针;
* @Member size: 数组的大小;
* @Member currentLen: 当前数组存放的个数
*/
typedef struct {
int *array;
int size;
int currentLen;
} Array;
/**
* 数组的创建
*
* @Param init_size 数组初始化容量
* @Return Array类型的变量(本地变量)
*/
Array array_create(int init_size);
/**
* 数组初始化,全部为0
*
* @Param int *a 指向数组内存空间的指针
*/
void array_init(Array *a);
/**
* 释放数组的内存空间
*
* @Param Array *a 指向要释放Array类型变量内存空间的指针
*/
void array_free(Array *a);
/**
* 获得数组的大小
*
* @Param Array *a 指向Array类型变量内存空间的指针
* @Return 数组的大小
*/
int array_size(const Array *a);
/**
* 获得数组下标对应的指针
*
* @Param Array *a 指向Array类型变量内存空间的指针
* @Param int index 数组下标
* @Return 数组下标对应的指针
*/
int * array_at(const Array *a, int index);
/**
* 获得数组下标所对应的值
*
* @Param Array *a 指向Array类型变量内存空间的指针
* @Param index 数组下标
*/
int array_get(const Array *a, int index);
/**
* 向数组指定下标存值
*
* @Param Array *a 指向Array类型变量内存空间的指针
* @Param index 数组下标
* @Param value 存入数组的值
*/
void array_set(Array *a, int value);
/**
* 数组的扩容
*
* @Param Array *a 指向Array类型变量内存空间的指针
* @Param more_size 额外扩容的空间
*/
void array_inflate(Array *a, int more_size);
/**
* 输出数组的基本信息
*/
void array_print(Array *a);
int main(int argc, char const *argv[]) {
const int capacity = 10; // 数组的初始容量
int max = 10; // 向数组中插入的数量
int i;
Array a = array_create(capacity);
for(i = 0; i < max; i++) {
array_set(&a, i*123);
}
array_print(&a);
array_free(&a);
return 0;
}
Array array_create(int init_size) {
Array a;
a.size = init_size;
a.array = (int*)malloc(sizeof(int) * a.size);
a.currentLen = 0;
array_init(&a);
return a;
}
void array_init(Array *a) {
int i;
for(i = 0; i < a->size; i++) {
a->array[i] = 0;
}
}
void array_free(Array *a) {
free(a->array);
a->array = NULL;
a->size = 0;
a->currentLen = 0;
return;
}
int array_size(const Array *a) {
return a->size;
}
int * array_at(const Array *a, int index) {
return &(a->array[index]);
}
int array_get(const Array *a, int index) {
return a->array[index];
}
void array_set(Array *a, int value) {
// 数组扩容
if(a->currentLen + 1 == a->size) {
array_inflate(a, a->size>>1);
}
a->array[a->currentLen++] = value;
}
void array_inflate(Array *a, int more_size) {
int i;
int newLen = a->size + more_size;
int *p = (int*)malloc(sizeof(int) * (newLen));
// 新建数组的初始化
for(i = 0; i < newLen; i++ ) {
p[i] = 0;
}
// 将旧数组的值拷贝到新数组中
for(i = 0; i < a->size; i++) {
p[i] = a->array[i];
}
free(a->array);
a->array = p;
a->size = newLen;
}
void array_print(Array *a) {
int i;
printf("数组的容量 = %d\n", a->size);
printf("数组使用的容量 = %d\n", a->currentLen);
printf("数组剩余容量 = %d\n", a->size - a->currentLen);
printf("content of array:\n");
for(i = 0; i < a->currentLen; i++) {
printf("%d ", a->array[i]);
}14.链表
14.1.创建链表
1、单链表二级指针头插法
#include <stdio.h>
#include <stdlib.h>
/**
* 定义结点
*/
typedef struct _node {
int value; // 值
struct _node *next; // 指向下一个结点
} Node;
/**
* 头插法
*/
void put(Node** head, int val) {
if(*head == NULL) {
*head = (Node*)malloc(sizeof(Node));
(*head)->value = val;
(*head)->next = NULL;
return;
}
Node* p = (Node*)malloc(sizeof(Node));
p->value = val;
p->next = *head;
*head = p;
}
/**
* 遍历
*/
void travel(Node* head) {
Node *p;
for(p = head; p != NULL; p = p->next) {
printf("%d\n", p->value);
}
}
int main(int argc, char const *argv[]) {
Node *head = NULL;
put(&head, 1);
put(&head, 2);
put(&head, 3);
travel(head);
return 0;
}2、定义链表结构头插法
#include <stdio.h>
#include <stdlib.h>
/**
* 定义结点
*/
typedef struct _node {
int value; // 值
struct _node *next; // 指向下一个结点
} Node;
/**
* 定义链表
*/
typedef struct _list {
Node* head; // 链表的头结点
} LinkedList;
/**
* 初始化链表
*/
LinkedList initLinkedList() {
LinkedList* list = (LinkedList*)malloc(sizeof(LinkedList));
list->head = NULL;
return *list;
}
/**
* 头插法
*/
void put(LinkedList *list, int val) {
if(list->head == NULL) {
list->head = (Node*)malloc(sizeof(Node));
list->head->value = val;
list->head->next = NULL;
return;
}
Node* p = (Node*)malloc(sizeof(Node));
p->value = val;
p->next = list->head;
list->head = p;
}
/**
* 遍历
*/
void travle(LinkedList *list) {
Node* p;
for(p = list->head; p != NULL; p = p->next) {
printf("%d\n", p->value);
}
}
int main(int argc, char const *argv[]) {
LinkedList linkedList = initLinkedList();
put(&linkedList, 1);
put(&linkedList, 2);
put(&linkedList, 3);
travle(&linkedList);
return 0;
}3、定义链表结构尾插法
#include <stdio.h>
#include <stdlib.h>
/**
* 定义结点
*/
typedef struct _node {
int value; // 值
struct _node *next; // 指向下一个结点
} Node;
/**
* 定义链表
*/
typedef struct _list {
Node* head; // 链表的头结点
Node* tail; // 链表的尾结点
} LinkedList;
/**
* 初始化链表
*/
LinkedList initLinkedList() {
LinkedList* list = (LinkedList*)malloc(sizeof(LinkedList));
list->head = NULL;
list->tail = NULL;
return *list;
}
/**
* 尾插法
*/
void put(LinkedList* list, int val) {
if(list->head == NULL) {
list->head = (Node*)malloc(sizeof(Node));
list->head->value = val;
list->tail = list->head;
list->tail->next = NULL;
return;
}
Node* p = (Node*)malloc(sizeof(Node));
p->value = val;
p->next = NULL;
list->tail->next = p;
list->tail = p;
}
/**
* 遍历
*/
void travle(LinkedList *list) {
Node* p;
for(p = list->head; p != NULL; p = p->next) {
printf("%d\n", p->value);
}
}
int main(int argc, char const *argv[]) {
LinkedList linkedlist = initLinkedList();
put(&linkedlist, 1);
put(&linkedlist, 2);
put(&linkedlist, 3);
travle(&linkedlist);
return 0;
}14.2.链表元素的删除和销毁
#include <stdio.h>
#include <stdlib.h>
/**
* 定义结点
*/
typedef struct _node {
int value; // 值
struct _node *next; // 指向下一个结点
} Node;
/**
* 定义链表
*/
typedef struct _list {
Node* head; // 链表的头结点
Node* tail; // 链表的尾结点
} LinkedList;
/**
* 初始化链表
*/
LinkedList initLinkedList() {
LinkedList* list = (LinkedList*)malloc(sizeof(LinkedList));
list->head = NULL;
list->tail = NULL;
return *list;
}
/**
* 尾插法
*/
void put(LinkedList* list, int val) {
if(list->head == NULL) {
list->head = (Node*)malloc(sizeof(Node));
list->head->value = val;
list->tail = list->head;
list->tail->next = NULL;
return;
}
Node* p = (Node*)malloc(sizeof(Node));
p->value = val;
p->next = NULL;
list->tail->next = p;
list->tail = p;
}
/**
* 遍历
*/
void travle(LinkedList *list) {
if(list->head == NULL) {
printf("链表不存在!\n");
return;
}
Node* p;
printf("LinkedList:");
for(p = list->head; p != NULL; p = p->next) {
printf("%d", p->value);
if(p->next) printf("->");
}
printf("\n");
}
/**
* 删除链表元素
*
* @Param LinkedList* list 目标链表
* @Param target 要删除的元素
*
* 这个方法一定要好好看,有错误
* 边界条件:如果删除的是头结点怎么办??
*/
int deleteLinkedListElement(LinkedList* list, int target) {
int count = 0;
Node* p;
Node* q;
// 删除头结点(边界情况)
while(list->head->value == target) {
// 将结点全部删除,所有节点都被释放,head就没有初始化了!
if(list->head == list->tail) {
free(list->head);
count++;
list->head = NULL;
break;
}
Node* temp = list->head;
list->head = list->head->next;
free(temp);
count++;
}
if(list->head == NULL) return count;
// 头结点存在的前提下才有如下操作
for(q = NULL, p = list->head; p != NULL; q = p, p = p->next) {
if(p->value == target) {
q->next = p->next;
free(p);
count++;
p = q; // 删除链表中所有的目标 如果break就是删除一个!
}
}
return count;
}
/**
* 销毁链表
*/
int destoryLinkedList(LinkedList *list) {
int cnt = 0;
Node *p;
Node *q;
for(p = list->head; p != NULL; p=q) {
q = p->next;
free(p);
cnt++;
}
list->head = list->tail = NULL;
return cnt;
}
int main(int argc, char const *argv[]) {
LinkedList linkedlist = initLinkedList(); // 初始化链表
int x;
int cnt = 0;
int val;
int delNum;
printf("请输入要插入的个数:\n");
scanf("%d", &x);
fflush(stdin);
printf("请输入插入的%d个整数:\n", x);
do {
scanf("%d", &val);
cnt++;
put(&linkedlist, val);
} while(cnt < x);
fflush(stdin);
printf("插入成功!您在链表中插入了%d个整数。\n", cnt);
travle(&linkedlist);
// destoryLinkedList(&linkedlist);
printf("请输入要删除的整数:\n");
scanf("%d", &delNum);
printf("删除的结点个数:%d\n", deleteLinkedListElement(&linkedlist, delNum));
travle(&linkedlist);
return 0;
}14.3.双向链表判断回文
#include <stdio.h>
#include <stdlib.h>
// 定义双向链表的结点
typedef struct _node {
struct _node* prev; // 前驱结点
char ch; // 存放的字符
struct _node* next; // 后继节点
} Node;
// 定义双向链表
typedef struct _douLinkedList {
Node* head;
Node* tail;
int size; // 当前双向链表结点的数量
} DouLinkedList;
// 双向链表的初始化
DouLinkedList init() {
DouLinkedList* list = (DouLinkedList*)malloc(sizeof(DouLinkedList));
list->head = NULL;
list->tail = NULL;
list->size = 0;
return *list;
}
// 插入
void put(DouLinkedList* list, char ch) {
// 如果头结点是NULL
if(!list->head) {
list->head = (Node*)malloc(sizeof(Node));
list->head->ch = ch;
list->head->next = NULL;
list->head->prev = NULL;
list->tail = list->head;
list->size += 1;
return;
}
// 头结点不是NULL
Node* node = (Node*)malloc(sizeof(Node));
node->ch = ch;
node->next = NULL;
node->prev = list->tail;
list->tail->next = node;
list->tail = node;
list->size += 1;
}
// head->tail 遍历
void travelHead2Tail(DouLinkedList* list) {
Node* p;
for(p = list->head; p; p = p->next) {
printf("%c", p->ch);
}
printf("\n");
}
// tail->head 遍历
void travelTail2Head(DouLinkedList* list) {
Node* p;
for(p = list->tail; p; p = p->prev) {
printf("%c", p->ch);
}
printf("\n");
}
/**
* 判断是否是回文
*
* 定义指针p指向双向链表的head, 指针q指向双向链表的tail。
* 判断回文,只需要将p向后移,q向前移即可,并判断p和q对应字符是否相等。
*
* 当链表结点数为奇数时,while循环的条件时p != q;
* 当链表结点数为偶数时,do-while循环的条件为 q->next != q;
*/
int isPalindrome(DouLinkedList* list) {
Node* p = list->head;
Node* q = list->tail;
int flag = 1; // 1是回文数 0不是回文数
if(list->size % 2 ) {
// 结点是奇数
while(p != q) {
if(p->ch != q->ch) {
// 不是回文数
flag = 0;
break;
}
p = p->next;
q = q->prev;
}
} else {
// 结点是偶数
do {
if(p->ch != q->ch) {
// 不是回文数
flag = 0;
break;
}
p = p->next;
q = q->prev;
} while(q->next != p);
}
return flag;
}
int main(int argc, char const *argv[]) {
char ch;
DouLinkedList list = init();
printf("请输入要检测的串(中间不要有空格,以回车结束):\n");
while((ch = getchar()) != '\n') {
put(&list, ch);
}
printf("\n-------------------正向输出-------------------\n");
travelHead2Tail(&list);
printf("结点个数: %d\n", list.size);
printf("\n-------------------逆向输出-------------------\n");
travelTail2Head(&list);
printf("结点个数: %d\n", list.size);
printf("\n-------------------是否是回文?-------------------\n");
printf("%s\n", isPalindrome(&list) ? "是" : "不是");
return 0;
}14.4.单链表反转

#include <stdio.h>
#include <stdlib.h>
// 定义结点
typedef struct _node {
char ch;
struct _node* next;
} Node;
// 定义单链表
typedef struct _linkedList {
Node* head; // 头结点
Node* tail; // 尾结点
int size; // 结点数量
} LinkedList;
// 初始化单链表
LinkedList init() {
LinkedList* list = (LinkedList*)malloc(sizeof(LinkedList));
list->head = NULL;
list->tail = NULL;
list->size = 0;
return *list;
}
// 插入
void put(LinkedList* list, char ch) {
if(!list->head) {
list->head = (Node*)malloc(sizeof(Node));
list->head->ch = ch;
list->head->next = NULL;
list->tail = list->head;
list->size = 1;
return;
}
Node* node = (Node*)malloc(sizeof(Node));
node->ch = ch;
node->next = NULL;
list->tail->next = node;
list->tail = node;
list->size += 1;
}
// 遍历
void travel(LinkedList* list) {
if(!list->size) {
printf("链表为空!\n");
return;
}
Node* p;
for(p = list->head; p; p = p->next) {
printf("%c", p->ch);
}
printf("\n");
}
// 单链表反转
void reverse(LinkedList* list) {
// 没有结点以下代码不需要执行
if(list->size == 0) return ;
// 只有一个结点不需要反转
if(list->size == 1) return;
Node* pNow = list->head;
Node* pPre = NULL;
Node* pNext = NULL;
// 单链表的反转
while(pNow) {
pNext = pNow->next;
pNow->next = pPre;
pPre = pNow;
pNow = pNext;
}
// 交换头尾指针
Node* temp = list->tail;
list->tail = list->head;
list->head = temp;
}
int main(int argc, char const *argv[]) {
LinkedList list = init();
char ch;
printf("请输入串(回车表示结束):\n");
while((ch = getchar()) != '\n') {
put(&list, ch);
}
printf("-----------遍历单链表-----------\n");
travel(&list);
printf("结点数量:%d\n", list.size);
// 单链表反转
reverse(&list);
printf("-----------反转后遍历单链表-----------\n");
travel(&list);
printf("结点数量:%d\n", list.size);
return 0;
}14.5.单链表是否存在环

#include <stdio.h>
#include <stdlib.h>
// 定义结点
typedef struct _node {
char ch;
struct _node* next;
} Node;
// 定义单链表
typedef struct _linkedList {
Node* head;
Node* tail;
int size;
} LinkedList;
// 初始化
LinkedList init() {
LinkedList* list = (LinkedList*)malloc(sizeof(LinkedList));
list->head = NULL;
list->tail = NULL;
list->size = 0;
return *list;
}
// 插入
void put(LinkedList* list, char ch) {
if(!list->head) {
list->head = (Node*)malloc(sizeof(Node));
list->head->ch = ch;
list->head->next = NULL;
list->tail = list->head;
list->size = 1;
return;
}
Node* node = (Node*)malloc(sizeof(Node));
node->ch = ch;
node->next = NULL;
list->tail->next = node;
list->tail = node;
list->size += 1;
}
// 遍历
void travel(LinkedList* list) {
if(!list->size) {
printf("单链表为空!\n");
return ;
}
Node* p;
for(p = list->head; p; p = p->next) {
printf("%c", p->ch);
}
printf("\n");
}
/**
* 判断单链表是否有环
* @Return 0 没有环 >0 有环代表环的长度
*/
int hasLoop(LinkedList* list) {
// 没有结点或者结点为1都返回0
if(list->size == 0 || list->size == 1) return 0;
int flag = 0; // 0代表不存在环 1代表存在环
int cnt = 0; // 计算环的个数
Node* fast; // 快指针
Node* slow; // 慢指针
fast = slow = list->head;
while(fast && fast->next) { // 考虑到链表结点个数有奇数有偶数
slow = slow->next;
fast = fast->next->next;
if(slow == fast) { // 表示单链表有环
flag = 1;
break;
}
}
// 如果有环就计算环的长度
if(flag) {
do {
fast = fast->next;
cnt++;
} while(slow != fast);
}
return cnt;
}
// 故意制造环
void addLoop(LinkedList* list) {
list->tail->next = list->head;
}
int main(int argc, char const *argv[]) {
LinkedList list = init();
char ch;
printf("请输入串(回车结束):\n");
while((ch = getchar()) != '\n') {
put(&list, ch);
}
// addLoop(&list);
printf("----------正常遍历单链表----------\n");
travel(&list);
printf("结点的数量:%d\n", list.size);
printf("----------单链表是否存在环?----------\n");
int numOfLoop = hasLoop(&list);
if(numOfLoop) {
printf("有环,长度为%d\n", numOfLoop);
} else {
printf("没有环\n");
}
return 0;
}14.6.合并两个有序单链表
#include <stdio.h>
#include <stdlib.h>
// 定义结点
typedef struct _node {
char ch;
struct _node* next;
} Node;
// 定义单链表
typedef struct _linkedList {
Node* head; // 头结点
Node* tail; // 尾结点
int size; // 单链表结点数
} LinkedList;
// 初始化单链表
LinkedList init() {
LinkedList* list = (LinkedList*)malloc(sizeof(LinkedList));
list->head = NULL;
list->tail = NULL;
list->size = 0;
return *list;
}
// 插入
void put(LinkedList* list, char ch) {
// 头结点为空
if(!list->head) {
list->head = (Node*)malloc(sizeof(Node));
list->head->ch = ch;
list->head->next = NULL;
list->tail = list->head;
list->size = 1;
return;
}
// 头结点不为空
Node* node = (Node*)malloc(sizeof(Node));
node->ch = ch;
node->next = NULL;
list->tail->next = node;
list->tail = node;
list->size += 1;
}
// 遍历
void travel(LinkedList* list) {
if(!list->head) {
printf("单链表不存在!\n");
return;
}
Node* p;
for(p = list->head; p; p = p->next) {
printf("%c", p->ch);
}
printf("\n");
}
/**
* 合并两个有序单链表
*
* @Param list1 有序单链表1
* @Param list2 有序单链表2
* @Return 合并后新的链表
*/
LinkedList merge(LinkedList* list1, LinkedList* list2) {
// list1和list2有一个为空就不需要执行合并操作
if(!list1->size || !list2->size) {
if(list1->size) {
return *list1;
}
return *list2;
}
LinkedList currentList = init(); // 要返回的新链表
Node* p = list1->head; // 指向list1的结点
Node* q = list2->head; // 指向list2的结点
Node* then; // list1或list2遍历完成之后继续遍历剩下的结点
while(p && q) {
if(p->ch > q->ch) { // 找到小的结点就继续向后移
put(¤tList, q->ch);
q = q->next;
} else {
put(¤tList, p->ch);
p = p->next;
}
}
if(!p) then = q; // 如果list1遍历完了,就继续遍历list2
if(!q) then = p; // 如果list2遍历完了,就继续遍历list1
while(then) {
put(¤tList, then->ch);
then = then->next;
}
return currentList;
}
int main(int argc, char const *argv[]) {
LinkedList list1 = init();
LinkedList list2 = init();
char ch;
printf("请输入串1(回车代表结束):\n");
while((ch = getchar()) != '\n') {
put(&list1, ch);
}
printf("请输入串2(回车代表结束):\n");
while((ch = getchar()) != '\n') {
put(&list2, ch);
}
printf("--------------------遍历单链表1--------------------\n");
travel(&list1);
printf("结点数量:%d\n", list1.size);
printf("--------------------遍历单链表2--------------------\n");
travel(&list2);
printf("结点数量:%d\n", list2.size);
printf("--------------------合并两个有序单链表--------------------\n");
LinkedList newList = merge(&list1, &list2);
travel(&newList);
printf("结点数量:%d\n", newList.size);
return 0;
}14.7.删除倒数第n个结点
#include <stdio.h>
#include <stdlib.h>
// 定义单链表结点
typedef struct _node {
char ch;
struct _node* next;
} Node;
// 定义单链表
typedef struct _linkedList {
Node* head;
Node* tail;
int size;
} LinkedList;
// 初始化单链表
LinkedList init() {
LinkedList* list = (LinkedList*)malloc(sizeof(LinkedList));
list->head = NULL;
list->tail = NULL;
list->size = 0;
return *list;
}
// 插入
void put(LinkedList* list, char ch) {
// head为空
if(!list->head) {
list->head = (Node*)malloc(sizeof(Node));
list->head->ch = ch;
list->head->next = NULL;
list->tail = list->head;
list->size = 1;
return;
}
// head不为空
Node* node = (Node*)malloc(sizeof(Node));
node->ch = ch;
node->next = NULL;
list->tail->next = node;
list->tail = node;
list->size += 1;
}
// 遍历
void travel(LinkedList* list) {
if(!list->size) {
printf("单链表为空\n");
return;
}
Node* p;
for(p = list->head; p; p = p->next) {
printf("%c", p->ch);
}
printf("\n");
}
/**
* 删除倒数第n个结点
*
* 思路:
* 1、定义快指针fast初始化为list->head, 向前先走n步;
* 2、定义慢指针slow初始化为list->head, 和fast一起向后走;
* 3、当fast到达list->tail的位置时,slow->next就是要删除的结点。
*/
void del(LinkedList* list, int n) {
// 单链表为空 或 n大于单链表的长度
if(!list->size || n > list->size || n <= 0) return;
// 删头结点
if(list->size == n) {
Node* p = list->head;
list->head = list->head->next;
free(p);
list->size -= 1;
return;
}
Node* fast; // 快指针
Node* slow; // 慢指针
Node* target; // 要删除的目标位置
fast = slow = list->head;
// 让快指针先走n步
int i = 1;
while(i <= n) {
fast = fast->next;
i++;
}
// 慢指针和快指针一起走,知道fast到tail的位置停止
while(fast->next) {
fast = fast->next;
slow = slow->next;
}
// 删除目标结点
target = slow->next;
slow->next = target->next;
free(target);
list->size -= 1;
}
int main(int argc, char const *argv[]) {
LinkedList list = init();
char ch;
int n;
printf("请输入串(回车代表结束):\n");
while((ch = getchar()) != '\n') {
put(&list, ch);
}
printf("\n-------------正常遍历单链表-------------\n");
travel(&list);
printf("单链表结点数%d\n", list.size);
printf("\n--------请输入要删除倒数第几个结点?--------\n");
scanf("%d", &n);
del(&list, n);
printf("\n-------------操作结果-------------\n");
travel(&list);
printf("单链表结点数%d\n", list.size);
return 0;
}14.8.单链表的中间结点
#include <stdio.h>
#include <stdlib.h>
// 定义结点
typedef struct _node {
char ch;
struct _node* next;
} Node;
// 定义链表
typedef struct _linkedList {
Node* head;
Node* tail;
int size;
} LinkedList;
// 初始化
LinkedList init() {
LinkedList* list = (LinkedList*)malloc(sizeof(LinkedList));
list->head = NULL;
list->tail = NULL;
list->size = 0;
return *list;
}
// 插入
void put(LinkedList* list, char ch) {
// head是NULL
if(!list->head) {
list->head = (Node*)malloc(sizeof(Node));
list->head->ch = ch;
list->head->next = NULL;
list->tail = list->head;
list->size = 1;
return ;
}
// head不是NULL
Node* node = (Node*)malloc(sizeof(Node));
node->ch = ch;
node->next = NULL;
list->tail->next = node;
list->tail = node;
list->size += 1;
}
/**
* 求链表的中间结点
*
* 思路:
* 1.定义快指针fast和慢指针slow初始化为list->head
* 2.fast每次走两步,slow每次走一步,当fast走到tail的时候slow刚好走到一半。
* 3.临界条件 fast && fast->next。
*/
Node* middle(LinkedList* list) {
if(!list->size || list->size == 1) return list->head;
Node* fast; // 快指针
Node* slow; // 慢指针
fast = slow = list->head; // 快慢指针的初始化
// 单链表长度分为奇偶,fast可能刚好在tail,也能在tail后面
while(fast && fast->next) {
fast = fast->next->next;
slow = slow->next;
}
return slow;
}
// 遍历
void travel(LinkedList* list) {
if(!list->size) {
printf("单链表为空\n");
return;
}
Node* p;
for(p = list->head; p; p = p->next) {
printf("%c", p->ch);
}
printf("\n");
}
int main(int argc, char const *argv[]) {
LinkedList list = init();
char ch;
printf("请输入串(回车表示结束):\n");
while((ch = getchar()) != '\n') {
put(&list, ch);
}
printf("\n------------正常遍历单链表------------\n");
travel(&list);
printf("单链表的结点数:%d\n", list.size);
printf("\n------------单链表的中间结点是?------------\n");
Node* midNode = middle(&list);
if(midNode) {
printf("%c\n", midNode->ch);
} else {
printf("该单链表没有中间结点!\n");
}
return 0;
}15.队列
15.1.循环队列
#include <stdio.h>
#include <stdlib.h>
/**
* 定义循环队列
* 循环队列元素个数 (r-f+n)%n
*/
typedef struct _circularQueue {
char* items; // 数组
int capacity; // 数组容量
int front; // 队头下标
int rear; // 队尾下标
} circularQueue;
// 初始化循环队列
circularQueue init(int capacity) {
circularQueue* queue = (circularQueue*)malloc(sizeof(circularQueue));
queue->capacity = capacity;
queue->items = (char*)malloc(sizeof(char) * queue->capacity);
queue->front = 0;
queue->rear = 0;
return *queue;
}
/**
* 是否队空
*
* @Return 1表示队空 0表示不空
*/
int isEmpty(circularQueue* queue) {
int flag = 0;
if(queue->front == queue->rear) {
flag = 1;
}
return flag;
}
/**
* 是否队满
*
* @Return 1表示队满 0表示队空
*/
int isFull(circularQueue* queue) {
int flag = 0;
if((queue->rear + 1) % queue->capacity == queue->front) {
flag = 1;
}
return flag;
}
/**
* 进队
*
* @Return 1表示入队成功 0表示入队失败
*/
int enQueue(circularQueue* queue, char ch) {
// 队满了
if(isFull(queue)) {
return 0;
}
queue->items[queue->rear] = ch;
queue->rear = (queue->rear + 1) % queue->capacity;
return 1;
}
/**
* 出队
*/
char* deQueue(circularQueue* queue) {
// 队空
if(isEmpty(queue)) {
return NULL;
}
char* ret = &queue->items[queue->front];
queue->front = (queue->front + 1) % queue->capacity;
return ret;
}
int main(int argc, char const *argv[]) {
circularQueue queue = init(5);
char ch;
printf("\n----------请在队列中插入值----------\n");
while((ch = getchar()) != '\n') {
enQueue(&queue, ch);
}
printf("\n----------全部出队----------\n");
while(!isEmpty(&queue)) {
printf("%c", *deQueue(&queue));
}
return 0;
}16.递归计算
16.1.递归重复计算
#include <stdio.h>
/**
* 案例:走台阶,每次可以走1步或2步
*
* 防止递归重复计算
*
* func(5)
* func(4)
* func(3)
* func(2)
* func(1)
* func(2)
* func(3)
* func(2)
* func(1)
* 5层台阶有8种走法
*
* 计算结果是対的,但是计算机发生了重复计算,效率会降低,
* 可以使用Map的key来存储n,value来存储func(n),如果Map中有,
* 就不要递归计算了!
*/
int func(int n) {
printf("func(%d)\n", n);
if(n == 1) return 1;
if(n == 2) return 2;
return func(n-1) + func(n-2);
}
int main(int argc, char const *argv[]) {
int n = 5;
printf("%d层台阶有%d种走法\n", n,func(5));
return 0;
}17.排序
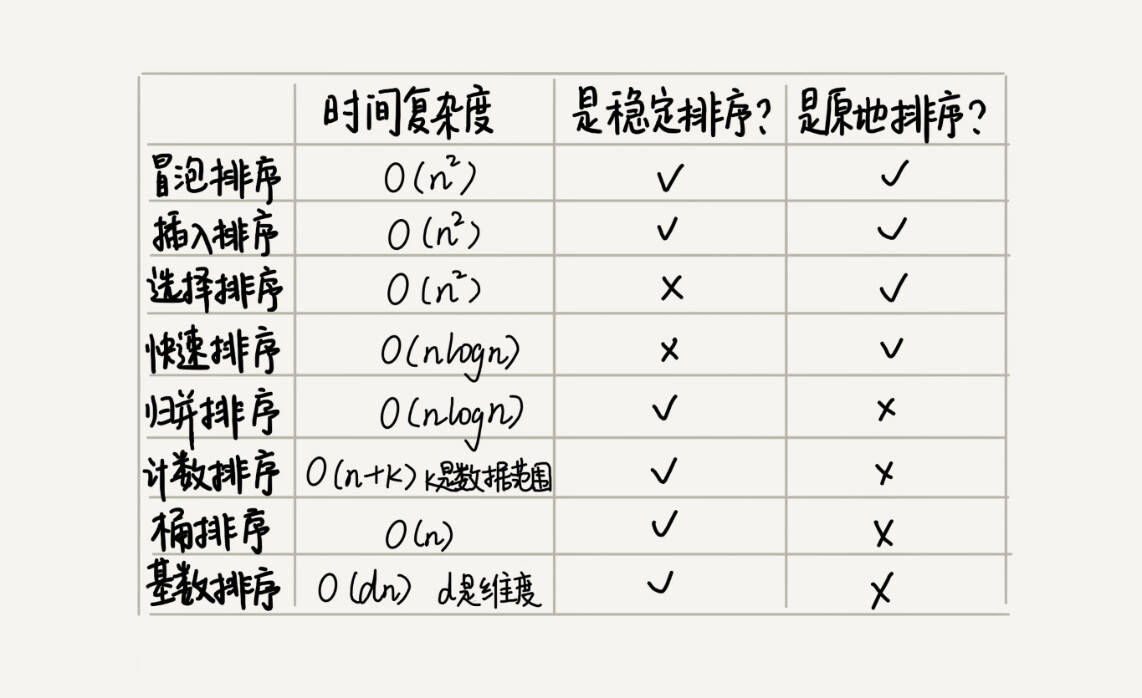
17.1.基于交换的排序
17.1.1.冒泡排序[O(n2)]
冒泡排序只会操作相邻的两个数据。每次冒泡操作都会对相邻的两个元素进行比较,看是否满足大小关系要求。如果不满足就让它俩互换。一次冒泡会让至少一个元素移动到它应该在的位置,重复 n 次,就完成了 n 个数据的排序工作。
我用一个例子,带你看下冒泡排序的整个过程。我们要对一组数据 4,5,6,3,2,1,从小到大进行排序。第一次冒泡操作的详细过程就是这样:
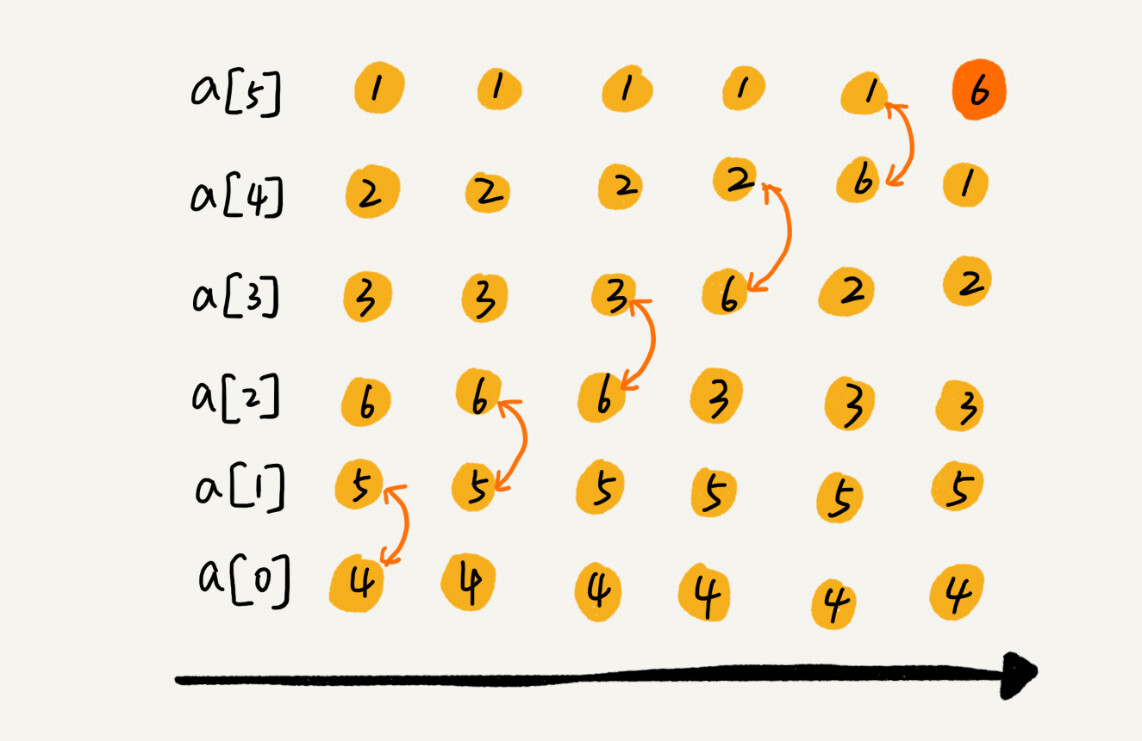
可以看出,经过一次冒泡操作之后,6 这个元素已经存储在正确的位置上。要想完成所有数据的排序,我们只要进行 6 次这样的冒泡操作就行了。

实际上,刚讲的冒泡过程还可以优化。当某次冒泡操作已经没有数据交换时,说明已经达到完全有序,不用再继续执行后续的冒泡操作。我这里还有另外一个例子,这里面给 6 个元素排序,只需要 4 次冒泡操作就可以了。
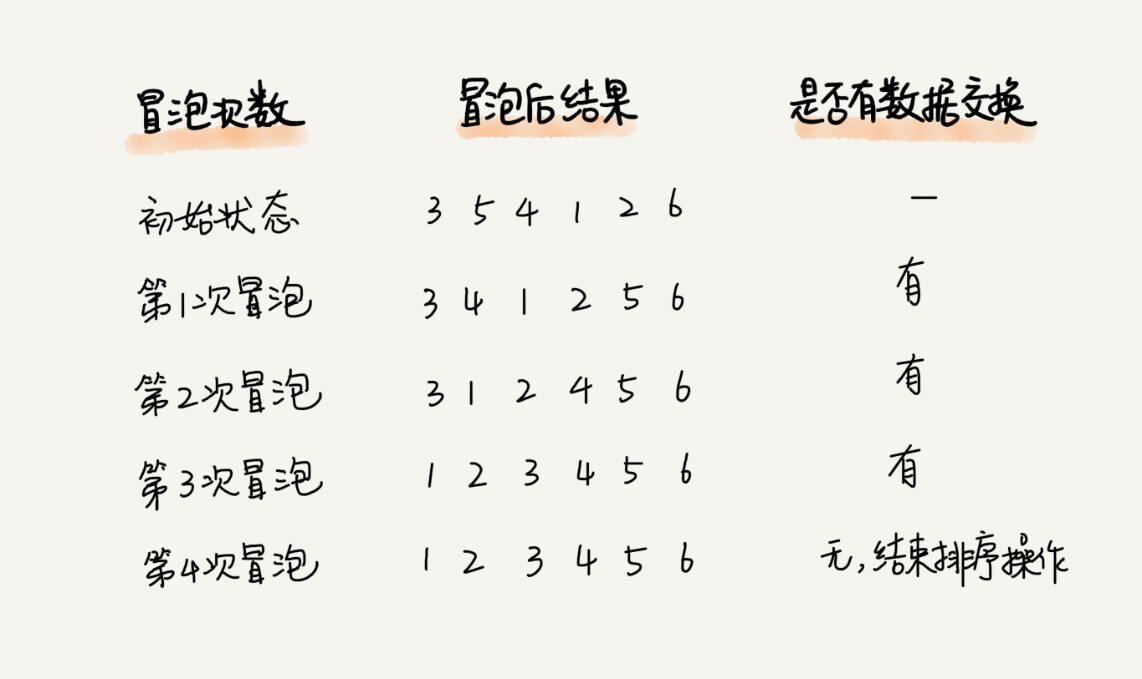
#include <stdio.h>
#define MAX_SIZE 6
void travel(int* a, int n);
void bubbleSort(int* a, int n);
int main(int argc, char const *argv[]) {
int a[] = {4, 5, 6, 3, 2, 1};
bubbleSort(a, MAX_SIZE);
printf("\n------------冒泡排序结果------------\n");
travel(a, MAX_SIZE);
return 0;
}
/**
* 冒泡排序
* 第1趟:4 5 3 2 1 6
* 第2趟:4 3 2 1 5 6
* 第3趟:3 2 1 4 5 6
* 第4趟:2 1 3 4 5 6
* 第5趟:1 2 3 4 5 6
* ------------冒泡排序结果------------
* 1 2 3 4 5 6
*
*/
void bubbleSort(int* a, int n) {
if(n <= 1) return; // 数组元素只有一个直接退出
for(int i = 1; i <= n; i++) { // 冒泡排序的趟数
int isSwap = 0; // 提前退出冒泡排序的标志位
for(int j = 1; j < n; j++) {
if(a[j] < a[j-1]) {
int temp = a[j];
a[j] = a[j-1];
a[j-1] = temp;
isSwap = 1;
}
}
if(!isSwap) break; // 没有数据交换提前退出
printf("第%d趟:", i);
travel(a, n);
}
}
// 遍历
void travel(int* a, int n) {
for(int i = 0; i < n; i++) {
printf("%d ", a[i]);
}
printf("\n");
}第一,冒泡排序是原地排序算法吗?
冒泡的过程只涉及相邻数据的交换操作,只需要常量级的临时空间,所以它的空间复杂度为 O(1),是一个原地排序算法。
第二,冒泡排序是稳定的排序算法吗?
在冒泡排序中,只有交换才可以改变两个元素的前后顺序。为了保证冒泡排序算法的稳定性,当有相邻的两个元素大小相等的时候,我们不做交换,相同大小的数据在排序前后不会改变顺序,所以冒泡排序是稳定的排序算法。
第三,冒泡排序的时间复杂度是多少?
最好情况下,要排序的数据已经是有序的了,我们只需要进行一次冒泡操作,就可以结束了,所以最好情况时间复杂度是 O(n)。而最坏的情况是,要排序的数据刚好是倒序排列的,我们需要进行 n 次冒泡操作,所以最坏情况时间复杂度为 O(n2)。
平均情况下的时间复杂度就是 O(n2)。

17.1.2.快速排序[O(nlogn)]
#include <stdio.h>
/**
* 交换数组元素
*/
void exchange(int* a, int index1, int index2) {
int temp = a[index1];
a[index1] = a[index2];
a[index2] = temp;
}
void travel(int* a, int n) {
for(int i = 0; i < n; i++) {
printf("%d ", a[i]);
}
printf("\n");
}
/**
* @param a 目标数组
* @param lo 开始下标
* @param hi 结束下标
* @return 快速排序的切分点
*/
int partition(int* a, int lo, int hi) {
int i = lo; // 从左向右扫描的指针
int j = hi + 1; // 从右向左扫描的指针
int v = a[lo]; // 切分数组的元素
while(true) {
while(a[++i] < v) if(i == hi) break; // 指针从左向右移动
while(v < a[--j]) if(j == lo) break; // 指针从右向左移动
if(i >= j) break; // 退出循环的临界条件
exchange(a, i, j); // 交换下标i,j的值
}
exchange(a, lo, j); // 将v=a[lo]放入正确的位置
return j;
}
void sort(int* a, int lo, int hi) {
if(hi <= lo) return; // 递归出口
int j = partition(a, lo, hi); // 获得数组切分点
sort(a, lo, j - 1);
sort(a, j + 1, hi);
}
int main(int argc, char const *argv[]) {
int a[] = {44, 69, 40, 98, 80, 25, 36, 96, 17, 11};
int n = sizeof(a) / sizeof(a[0]);
sort(a, 0, n - 1);
printf("\n------------快速排序结果------------\n");
travel(a, n);
return 0;
}快排是一种原地、不稳定的排序算法。
如果数组中的数据原来已经是有序的了,比如 1,3,5,6,8。每次分区我们平均要扫描大约 n/2 个元素,这种情况下,快排的时间复杂度就从 O(nlogn) 退化成了 O(n2)。
17.2.基于插入的排序
17.2.1.插入排序[O(n2)]
如图所示,要排序的数据是 4,5,6,1,3,2,其中左侧为已排序区间,右侧是未排序区间。

插入排序也包含两种操作,一种是元素的比较,一种是元素的移动。当我们需要将一个数据 a 插入到已排序区间时,需要拿 a 与已排序区间的元素依次比较大小,找到合适的插入位置。找到插入点之后,我们还需要将插入点之后的元素顺序往后移动一位,这样才能腾出位置给元素 a 插入
#include <stdio.h>
void insertSort(int* a, int n);
void travel(int* a, int n);
int main(int argc, char const *argv[]) {
int a[] = {44, 69, 40, 98, 80, 25, 36, 96, 17, 11};
int n = sizeof(a) / sizeof(a[0]); // 获得数组的长度
insertSort(a, n);
printf("\n----------插入排序结果----------\n");
travel(a, n);
return 0;
}
/**
* 插入排序
*
* 思路:
* 1.初始化i=1,用temp来保存a[i]的值。
* 2.如果temp比前面的元素小,前面元素就向后移动。
* 3.直到没有元素比temp大了,空出的位置就是temp的要插入的位置。
*
* i = 1:44 69 40 98 80 25 36 96 17 11
* i = 2:40 44 69 98 80 25 36 96 17 11
* i = 3:40 44 69 98 80 25 36 96 17 11
* i = 4:40 44 69 80 98 25 36 96 17 11
* i = 5:25 40 44 69 80 98 36 96 17 11
* i = 6:25 36 40 44 69 80 98 96 17 11
* i = 7:25 36 40 44 69 80 96 98 17 11
* i = 8:17 25 36 40 44 69 80 96 98 11
* i = 9:11 17 25 36 40 44 69 80 96 98
*
* ----------插入排序结果----------
* 11 17 25 36 40 44 69 80 96 98
*/
void insertSort(int* a, int n) {
for(int i = 1; i < n; i++) {
int temp = a[i]; // 用temp来保存当前的值
int j = i;
while(j > 0 && temp < a[j-1]) { // 如果temp比前面的值小,前面的值就向后移
a[j] = a[j-1];
j--;
}
a[j] = temp; // 最后将temp插入到指定位置
printf("i = %d:", i);
travel(a, n);
}
}
// 遍历
void travel(int* a, int n) {
for(int i = 0; i < n; i++) {
printf("%d ", a[i]);
}
printf("\n");
}第一,插入排序是原地排序算法吗?
从实现过程可以很明显地看出,插入排序算法的运行并不需要额外的存储空间,所以空间复杂度是 O(1),也就是说,这是一个原地排序算法。
第二,插入排序是稳定的排序算法吗?
在插入排序中,对于值相同的元素,我们可以选择将后面出现的元素,插入到前面出现元素的后面,这样就可以保持原有的前后顺序不变,所以插入排序是稳定的排序算法。
第三,插入排序的时间复杂度是多少?
如果要排序的数据已经是有序的,我们并不需要搬移任何数据。如果我们从尾到头在有序数据组里面查找插入位置,每次只需要比较一个数据就能确定插入的位置。所以这种情况下,最好是时间复杂度为 O(n)。注意,这里是从尾到头遍历已经有序的数据。
如果数组是倒序的,每次插入都相当于在数组的第一个位置插入新的数据,所以需要移动大量的数据,所以最坏情况时间复杂度为 O(n2)。
对于插入排序来说,每次插入操作都相当于在数组中插入一个数据,循环执行 n 次插入操作,所以平均时间复杂度为 O(n2)。
17.3.基于选择的排序
17.3.1.简单选择排序[O(n2)]
选择排序算法的实现思路有点类似插入排序,也分已排序区间和未排序区间。但是选择排序每次会从未排序区间中找到最小的元素,将其放到已排序区间的末尾。
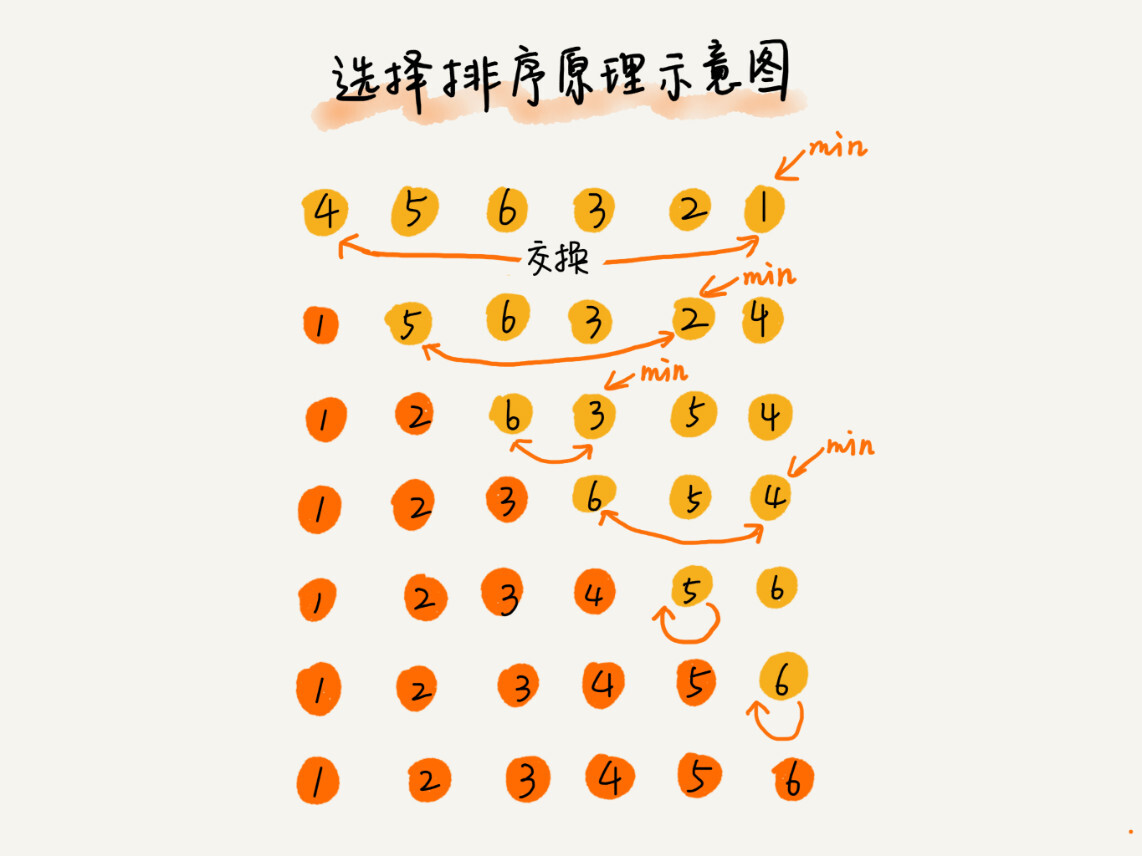
#include <stdio.h>
// 遍历
void travel(int* a, int n) {
for(int i = 0; i < n; i++) {
printf("%d ", a[i]);
}
printf("\n");
}
/**
* 简单选择排序:不断的选出剩余元素之中的最小者
*
* i = 0:11 69 40 98 80 25 36 96 17 44
* i = 1:11 17 40 98 80 25 36 96 69 44
* i = 2:11 17 25 98 80 40 36 96 69 44
* i = 3:11 17 25 36 80 40 98 96 69 44
* i = 4:11 17 25 36 40 80 98 96 69 44
* i = 5:11 17 25 36 40 44 98 96 69 80
* i = 6:11 17 25 36 40 44 69 96 98 80
* i = 7:11 17 25 36 40 44 69 80 98 96
* i = 8:11 17 25 36 40 44 69 80 96 98
* i = 9:11 17 25 36 40 44 69 80 96 98
* -----------简单选择排序结果-----------
* 11 17 25 36 40 44 69 80 96 98
*
*/
void selectSort(int* a, int n) {
for(int i = 0; i < n; i++) {
int min = i;
for(int j = i + 1; j < n; j++) {
if(a[j] < a[min]) {
min = j;
}
}
int temp = a[i];
a[i] = a[min];
a[min] = temp;
printf("i = %d:", i);
travel(a, n);
}
}
int main(int argc, char const *argv[]) {
int a[] = {44, 69, 40, 98, 80, 25, 36, 96, 17, 11};
int n = sizeof(a) / sizeof(a[0]);
selectSort(a, n);
printf("\n-----------简单选择排序结果-----------\n");
travel(a, n);
return 0;
}首先,选择排序空间复杂度为 O(1),是一种原地排序算法。
选择排序的最好情况时间复杂度、最坏情况和平均情况时间复杂度都为 O(n2)。
简单选择排序是不稳定排序。
17.4.归并排序[(nlogn)]
如果要排序一个数组,我们先把数组从中间分成前后两部分,然后对前后两部分分别排序,再将排好序的两部分合并在一起,这样整个数组就都有序了。
#include <stdio.h>
#include <stdlib.h>
#define MAX_SIZE 10
// 遍历
void travel(int* a, int n) {
for(int i = 0; i < n; i++) {
printf("%d ", a[i]);
}
printf("\n");
}
/**
* 归并
*
* 将a[lo...mid]和a[mid+1...hi]归并
* 前提:a[lo...mid]和a[mid+1...hi]都是有序的!
*
* @param a 目标数组
* @param aux 辅助数组
* @param lo 开始下标
* @param mid 中间下标
* @param hi 结束下标
*/
void merge(int* a, int lo, int mid, int hi) {
int i = lo; // i代表aux数组aux[lo, mid]的下标
int j = mid + 1; // i代表aux数组aux[mid + 1, hi]的下标
int* aux = (int*)malloc(sizeof(int) * MAX_SIZE);
// 将a[lo..hi]复制到aux[lo..hi]
for(int k = lo; k <= hi; k++) {
aux[k] = a[k];
}
// 将aux数组归并到a数组中
for(int k = lo; k <= hi; k++) { // k代表a数组的下标
if(i > mid)
a[k] = aux[j++];
else if(j > hi)
a[k] = aux[i++];
else if(aux[j] < aux[i])
a[k] = aux[j++];
else
a[k] = aux[i++];
}
free(aux);
}
/**
* 归并排序
*
* @param a 目标数组
* @param lo 开始下标
* @param hi 结束下标
*/
void sort(int* a, int lo, int hi) {
if(hi <= lo) return; // 递归的出口
int mid = (lo + hi) / 2; // 计算mid中间值
sort(a, lo, mid); // 将左半边排序
sort(a, mid + 1, hi); // 将右半边排序
merge(a, lo, mid, hi); // 归并结果
}
int main(int argc, char const *argv[]) {
int a[] = {44, 69, 40, 98, 80, 25, 36, 96, 17, 11};
int n = sizeof(a) / sizeof(a[0]);
sort(a, 0, n - 1);
printf("\n--------------归并排序结果--------------\n");
travel(a, n);
return 0;
}第一,归并排序是稳定的排序算法吗?
归并排序稳不稳定关键要看 merge() 函数,也就是两个有序子数组合并成一个有序数组的那部分代码。归并排序是一个稳定的排序算法。
第二,归并排序的时间复杂度是多少?
归并排序的执行效率与要排序的原始数组的有序程度无关,所以其时间复杂度是非常稳定的,不管是最好情况、最坏情况,还是平均情况,时间复杂度都是 O(nlogn)。
第三,归并排序的空间复杂度是多少?
临时内存空间最大也不会超过 n 个数据的大小,所以空间复杂度是 O(n)。
17.5.基数排序[O(n)]
手机号码有 11 位,范围太大,显然不适合用这两种排序算法。针对这个排序问题,有没有时间复杂度是 O(n) 的算法呢?先按照最后一位来排序手机号码,然后,再按照倒数第二位重新排序,以此类推,最后按照第一位重新排,经过 11 次排序之后,手机号码就都有序了。
注意,这里按照每位来排序的排序算法要是稳定的,否则这个实现思路就是不正确的。因为如果是非稳定排序算法,那最后一次排序只会考虑最高位的大小顺序,完全不管其他位的大小关系,那么低位的排序就完全没有意义了。
基数排序的时间复杂度就近似于 O(n)。
基数排序对要排序的数据是有要求的,需要可以分割出独立的“位”来比较,而且位之间有递进的关系,如果 a 数据的高位比 b 数据大,那剩下的低位就不用比较了。除此之外,每一位的数据范围不能太大,要可以用线性排序算法来排序,否则,基数排序的时间复杂度就无法做到 O(n) 了。
